MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction
Sintesi del comunicato stampa
I ricercatori di Meta e della Rice University hanno sviluppato MetaEmbed, un nuovo approccio alla ricerca multimodale che consente ai sistemi di regolare a richiesta la propria accuratezza e velocità. Gli attuali sistemi di recupero multimodale, che effettuano ricerche su testo e immagini, devono affrontare un compromesso tra precisione ed efficienza computazionale: o comprimono tutto in un singolo vettore che perde dettagli, oppure utilizzano centinaia di vettori che diventano troppo lenti per un uso pratico. MetaEmbed introduce i "Meta Token" apprendibili che creano un piccolo insieme di embedding contestualizzati organizzati dalle informazioni a grana grossa a quelle a grana fine. Questo design consente agli utenti di selezionare quanti vettori utilizzare durante la ricerca, bilanciando la qualità rispetto alle esigenze di velocità. I test sui benchmark standard mostrano che il sistema raggiunge prestazioni allo stato dell'arte mantenendo lo scaling
abstract
I modelli universali di embedding multimodale hanno ottenuto un grande successo nel catturare la rilevanza semantica tra query e candidati. Tuttavia, i metodi attuali o condensano query e candidati in un singolo vettore, limitando potenzialmente l'espressività delle informazioni a grana fine, oppure producono troppi vettori, risultando proibitivi per il recupero multi-vettore. In questo lavoro presentiamo MetaEmbed, un nuovo framework per il recupero multimodale che ripensa il modo in cui gli embedding multimodali vengono costruiti e fatti interagire su larga scala. Durante l'addestramento, un numero fisso di Meta Token apprendibili viene aggiunto alla sequenza di input. In fase di test, le loro rappresentazioni contestualizzate dell'ultimo livello fungono da embedding multi-vettore compatti ma espressivi. Attraverso l'addestramento Matryoshka Multi-Vector Retrieval proposto, MetaEmbed impara a organizzare le informazioni per granularità tra più vettori. Di conseguenza, abilitiamo lo scaling in fase di test nel recupero multimodale, dove gli utenti possono bilanciare la qualità del recupero rispetto alle esigenze di efficienza selezionando il numero di token utilizzati per l'indicizzazione e le interazioni di recupero. Valutazioni estese sul Massive Multimodal Embedding Benchmark (MMEB) e sul Visual Document Retrieval Benchmark (ViDoRe) confermano che MetaEmbed raggiunge prestazioni di recupero allo stato dell'arte mantenendo uno scaling robusto fino a modelli con 32B parametri. Il codice è disponibile all'indirizzo https://github.com/facebookresearch/MetaEmbed.
dettagli
citazione
@inproceedings{xiao2026metaembed,
title = {MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction},
author = {Xiao, Zilin and Ma, Qi and Gu, Mengting and Chen, Chun-cheng Jason and Chen, Xintao and Ordonez, Vicente and Mohan, Vijai},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2509.18095},
}
domande, principali contributi e limiti di questo articolo generati automaticamente
Domande a cui questo articolo aiuta a rispondere
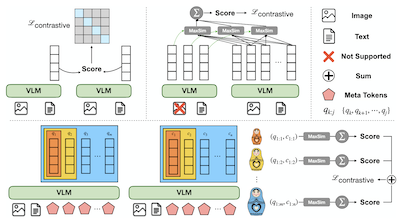
- Cos'è MetaEmbed e quale problema affronta? MetaEmbed è un framework di recupero multimodale che utilizza Meta Token apprendibili e compatti per fornire un recupero più espressivo rispetto agli embedding a vettore singolo, senza il pesante costo di centinaia di vettori a livello di patch.
- Come abilita MetaEmbed lo scaling in fase di test? Addestra gruppi annidati di Meta Embedding attraverso il Matryoshka Multi-Vector Retrieval, così che gli utenti possano scegliere budget di recupero più piccoli o più grandi al momento dell'indicizzazione e del punteggio senza dover riaddestrare.
- Perché i Meta Token sono utili per il recupero multimodale? I loro stati contestualizzati dell'ultimo livello fungono da un piccolo insieme di embedding multi-vettore che preservano le interazioni a grana fine tra query e candidati, mantenendo al contempo controllabili la dimensione dell'indice e il costo del calcolo del punteggio.
- Quanto bene si comporta MetaEmbed su MMEB? L'articolo riporta che MetaEmbed inizializzato con Qwen2.5-VL raggiunge un Precision@1 complessivo di 76.6 con un modello da 7B e di 78.7 con un modello da 32B, superando i baseline elencati.
- MetaEmbed funziona per il recupero di documenti visivi? Sì, l'articolo lo valuta su ViDoRe e mostra che la qualità del recupero migliora all'aumentare dei Meta Embedding utilizzati, mentre MMR preserva prestazioni elevate a budget di recupero ridotti.
Principali contributi
- L'articolo introduce i Meta Token come embedding multi-vettore contestualizzati e compatti per il recupero multimodale su query e candidati di tipo testuale, visivo e a modalità mista.
- Il Matryoshka Multi-Vector Retrieval addestra gruppi di embedding annidati dal grossolano al fine, consentendo a un singolo modello e a un singolo design di indice di supportare più punti operativi di qualità-latenza.
- MetaEmbed raggiunge risultati allo stato dell'arte su MMEB e risultati solidi su ViDoRe, mantenendo lo scaling fino a backbone di modelli visione-linguaggio da 32B.
- Gli studi di ablazione mostrano che i benefici del recupero multi-vettore crescono con la scala del modello e che MMR è importante per preservare la qualità del recupero a basso budget.
- L'analisi di efficienza mostra che la latenza del calcolo del punteggio rimane contenuta per budget moderati e che la memoria dell'indice può essere gestita scegliendo impostazioni di recupero bilanciate.
Limiti e avvertenze
- Budget di recupero più elevati aumentano la memoria dell'indice, ma il design annidato rende questo un compromesso controllabile dall'utente anziché un costo di deployment fisso.
- Il budget più grande può aumentare sostanzialmente i FLOP del calcolo del punteggio, eppure la latenza misurata rimane pratica per molti scenari e l'articolo mostra un'accuratezza utile a budget molto più piccoli.
- MetaEmbed richiede comunque il fine-tuning di backbone VLM potenti, quindi lavori futuri potrebbero esplorare ricette di addestramento più leggere; la configurazione LoRA e gli esperimenti su più architetture rendono già l'approccio ampiamente accessibile.
- La valutazione si concentra sui benchmark standard di recupero multimodale e di documenti visivi, lasciando come studi di deployment naturali gli indici di produzione molto grandi e i domini aziendali specializzati.
- Il metodo è orientato al recupero piuttosto che direttamente alla generazione o al question answering, ma un recupero flessibile migliore è un prezioso elemento costitutivo per i sistemi multimodali con retrieval-augmented generation.
Come interpretare questo risultato
Questo articolo si legge al meglio come un solido contributo al recupero multimodale scalabile: MetaEmbed preserva l'interazione tardiva a grana fine, aggiunge una pratica leva per regolare il budget in fase di test e mostra che i VLM più grandi possono diventare modelli di recupero più efficaci quando dotati di interfacce multi-vettore compatte.