Obj2Text: Generating Visually Descriptive Language from Object Layouts
Resumen de prensa
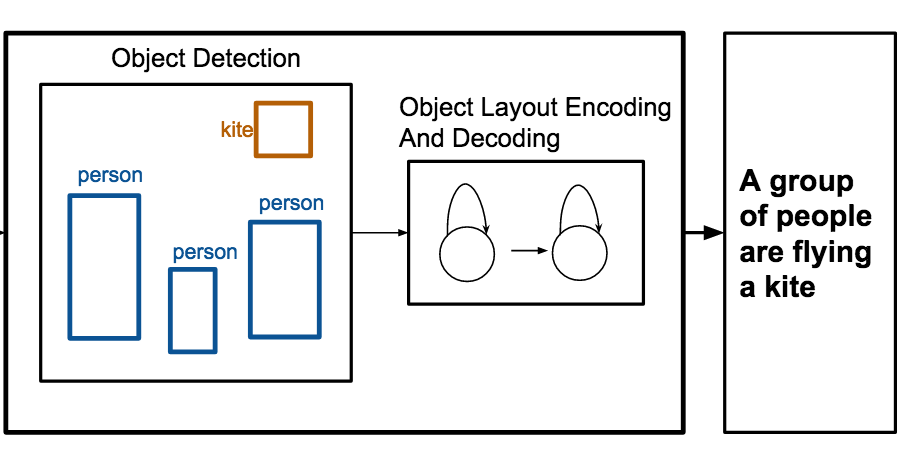
Investigadores de la Universidad de Virginia han construido un sistema que puede escribir automáticamente subtítulos que describen una escena usando nada más que una lista de objetos y sus posiciones en una imagen, prescindiendo de la necesidad de datos de píxeles en bruto. El sistema, llamado OBJ2TEXT, funciona introduciendo las etiquetas de los objetos y las coordenadas de sus cuadros delimitadores en una red neuronal que codifica la disposición como una secuencia, y luego pasando esa representación codificada a una segunda red neuronal que genera una oración palabra por palabra. Al realizar pruebas con el conjunto de datos estándar de imágenes MS-COCO, el equipo descubrió que tanto la ubicación de los objetos como su cantidad mejoraban de forma significativa la calidad de los subtítulos —eliminar cualquiera de los dos provocaba caídas medibles en el rendimiento—, lo que demuestra que incluso una codificación secuencial de la información espacial aporta un valor descriptivo real. Quizás de forma más práctica, cuando los investigadores combinaron OBJ2TEXT con un detector de objetos llamado YOLO y un modelo convencional de generación de subtítulos basado en imágenes, el sistema híbrido superó a la línea base de generación de subtítulos basada solo en imágenes, elevando su puntuación CIDEr de 0,863 a 0,950 en el benchmark MS-COCO; los evaluadores humanos también prefirieron los subtítulos del sistema combinado aproximadamente el 65 por ciento de las veces cuando todos coincidían. El trabajo es importante porque muestra que la información estructurada y simbólica sobre una escena —del tipo que producen los detectores de objetos o que se usa en el diseño gráfico y los storyboards— puede complementar o incluso sustituir parcialmente a las características visuales a nivel de píxel en la generación de lenguaje, ofreciendo una forma más limpia de estudiar qué necesitan saber realmente sobre una escena los modelos de generación de subtítulos de imágenes.
resumen
Generar subtítulos para imágenes es una tarea que recientemente ha recibido considerable atención. En este trabajo nos centramos en la generación de subtítulos para escenas abstractas, o disposiciones de objetos, donde la única información proporcionada es un conjunto de objetos y sus ubicaciones. Proponemos OBJ2TEXT, un modelo secuencia a secuencia que codifica un conjunto de objetos y sus ubicaciones como una secuencia de entrada mediante una red LSTM, y decodifica esta representación usando un modelo de lenguaje LSTM. Mostramos que nuestro modelo, a pesar de codificar las disposiciones de objetos como una secuencia, puede representar relaciones espaciales entre objetos y generar descripciones que son globalmente coherentes y semánticamente relevantes. Probamos nuestro enfoque en una tarea de generación de subtítulos de disposiciones de objetos usando únicamente anotaciones de objetos como entradas. Adicionalmente, mostramos que nuestro modelo, combinado con un detector de objetos de última generación, mejora un modelo de generación de subtítulos de imágenes de 0,863 a 0,950 (puntuación CIDEr) en el benchmark de prueba de la tarea estándar de generación de subtítulos MS-COCO.
detalles
cita
@inproceedings{yin2017obj,
title = {Obj2Text: Generating Visually Descriptive Language from Object Layouts},
author = {Yin, Xuwang and Ordonez, Vicente},
year = {2017},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2017},
url = {https://arxiv.org/abs/1707.07102},
}