보도 자료 요약
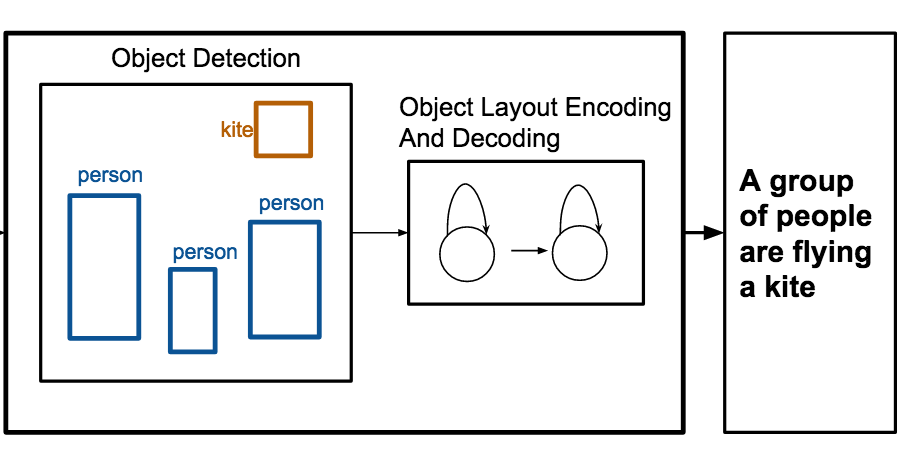
버지니아 대학교의 연구자들은 원시 픽셀 데이터의 필요성을 우회하여, 이미지 속 객체 목록과 그 위치만으로 장면을 설명하는 캡션을 자동으로 작성할 수 있는 시스템을 구축했다. OBJ2TEXT라 불리는 이 시스템은 객체 레이블과 그 바운딩 박스 좌표를 레이아웃을 시퀀스로 인코딩하는 하나의 신경망에 입력한 다음, 그 인코딩된 표현을 단어 단위로 문장을 생성하는 두 번째 신경망에 전달하는 방식으로 작동한다. 표준 MS-COCO 이미지 데이터셋에서 시험한 결과, 연구팀은 객체 위치와 객체 개수가 모두 캡션 품질을 유의미하게 향상시킨다는 것 — 둘 중 하나를 제거하면 측정 가능한 성능 하락이 발생했다 — 을 발견하여, 공간 정보의 순차적 인코딩조차 실질적인 설명적 가치를 지님을 입증했다. 아마 더 실용적으로는, 연구자들이 OBJ2TEXT를 YOLO라는 객체 탐지기 및 기존의 이미지 기반 캡셔닝 모델과 결합했을 때, 이 하이브리드 시스템은 이미지만 사용하는 캡셔닝 기준선을 능가하여 MS-COCO 벤치마크에서 그 CIDEr 점수를 0.863에서 0.950으로 끌어올렸으며, 인간 평가자들도 모두가 동의했을 때 약 65퍼센트의 경우에 결합 시스템의 캡션을 선호했다. 이 연구가 중요한 이유는, 객체 탐지기가 생성하거나 그래픽 디자인 및 스토리보딩에 사용되는 종류의 장면에 관한 구조화된 기호적 정보가 언어 생성에서 픽셀 수준의 시각 특징을 보완하거나 심지어 부분적으로 대체할 수 있음을 보여주어, 이미지 캡셔닝 모델이 장면에 대해 실제로 무엇을 알 필요가 있는지를 연구하는 더 깔끔한 방법을 제공하기 때문이다.
초록
이미지에 대한 캡션을 생성하는 것은 최근 상당한 주목을 받은 작업이다. 본 연구에서 우리는 추상적 장면, 즉 제공되는 유일한 정보가 객체 집합과 그 위치인 객체 레이아웃에 대한 캡션 생성에 초점을 맞춘다. 우리는 객체 집합과 그 위치를 LSTM 네트워크를 사용해 입력 시퀀스로 인코딩하고, 이 표현을 LSTM 언어 모델을 사용해 디코딩하는 시퀀스-투-시퀀스 모델인 OBJ2TEXT를 제안한다. 우리는 우리의 모델이 객체 레이아웃을 시퀀스로 인코딩함에도 불구하고 객체 간의 공간적 관계를 표현하고, 전역적으로 일관되며 의미적으로 관련 있는 설명을 생성할 수 있음을 보인다. 우리는 객체 주석만을 입력으로 사용하여 객체 레이아웃 캡셔닝 작업에서 우리의 접근법을 시험한다. 추가로, 우리는 우리의 모델이 최첨단 객체 탐지기와 결합될 때 표준 MS-COCO Captioning 작업의 테스트 벤치마크에서 이미지 캡셔닝 모델을 0.863에서 0.950(CIDEr 점수)으로 향상시킴을 보인다.
세부 정보
인용
@inproceedings{yin2017obj,
title = {Obj2Text: Generating Visually Descriptive Language from Object Layouts},
author = {Yin, Xuwang and Ordonez, Vicente},
year = {2017},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2017},
url = {https://arxiv.org/abs/1707.07102},
}