Obj2Text: Generating Visually Descriptive Language from Object Layouts
Résumé du communiqué de presse
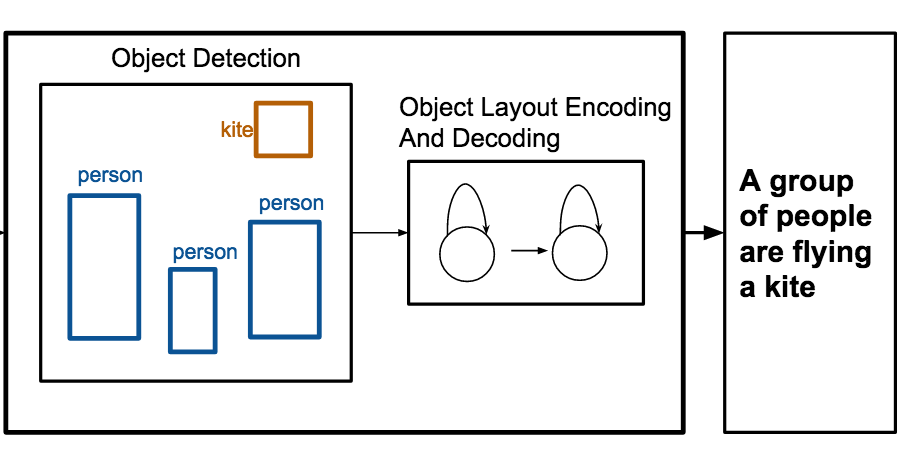
Des chercheurs de l'Université de Virginie ont construit un système capable de rédiger automatiquement des légendes décrivant une scène à partir de rien de plus qu'une liste d'objets et de leurs positions dans une image, contournant ainsi le besoin de données de pixels brutes. Le système, appelé OBJ2TEXT, fonctionne en introduisant les étiquettes d'objets et les coordonnées de leurs boîtes englobantes dans un premier réseau de neurones qui encode l'agencement sous forme de séquence, puis en transmettant cette représentation encodée à un second réseau de neurones qui génère une phrase mot à mot. Lors de tests sur le jeu de données d'images standard MS-COCO, l'équipe a constaté que l'emplacement des objets et leur nombre amélioraient tous deux significativement la qualité des légendes — la suppression de l'un ou de l'autre entraînait des baisses de performance mesurables — démontrant que même un encodage séquentiel de l'information spatiale comporte une réelle valeur descriptive. De manière peut-être plus pratique, lorsque les chercheurs ont combiné OBJ2TEXT avec un détecteur d'objets appelé YOLO et un modèle classique de génération de légendes fondé sur l'image, le système hybride a surpassé la référence de génération de légendes à partir de la seule image, faisant passer son score CIDEr de 0,863 à 0,950 sur le banc d'essai MS-COCO ; les évaluateurs humains ont également préféré les légendes du système combiné dans environ 65 pour cent des cas lorsqu'ils étaient tous d'accord. Ce travail est important parce qu'il montre que des informations structurées et symboliques sur une scène — du type de celles produites par les détecteurs d'objets ou utilisées en design graphique et en storyboarding — peuvent compléter, voire partiellement remplacer, les caractéristiques visuelles au niveau du pixel dans la génération de langage, offrant une manière plus nette d'étudier ce que les modèles de génération de légendes ont réellement besoin de savoir au sujet d'une scène.
résumé
La génération de légendes pour les images est une tâche qui a récemment suscité une attention considérable. Dans ce travail, nous nous concentrons sur la génération de légendes pour des scènes abstraites, ou agencements d'objets, où la seule information fournie est un ensemble d'objets et leurs emplacements. Nous proposons OBJ2TEXT, un modèle séquence à séquence qui encode un ensemble d'objets et leurs emplacements sous forme de séquence d'entrée à l'aide d'un réseau LSTM, et décode cette représentation à l'aide d'un modèle de langue LSTM. Nous montrons que notre modèle, bien qu'il encode les agencements d'objets sous forme de séquence, peut représenter les relations spatiales entre les objets et générer des descriptions globalement cohérentes et sémantiquement pertinentes. Nous testons notre approche dans une tâche de génération de légendes d'agencements d'objets en utilisant uniquement les annotations d'objets comme entrées. Nous montrons en outre que notre modèle, combiné à un détecteur d'objets à l'état de l'art, améliore un modèle de génération de légendes d'images de 0,863 à 0,950 (score CIDEr) sur le banc d'essai de test de la tâche standard MS-COCO Captioning.
détails
citation
@inproceedings{yin2017obj,
title = {Obj2Text: Generating Visually Descriptive Language from Object Layouts},
author = {Yin, Xuwang and Ordonez, Vicente},
year = {2017},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2017},
url = {https://arxiv.org/abs/1707.07102},
}