プレスリリース要約
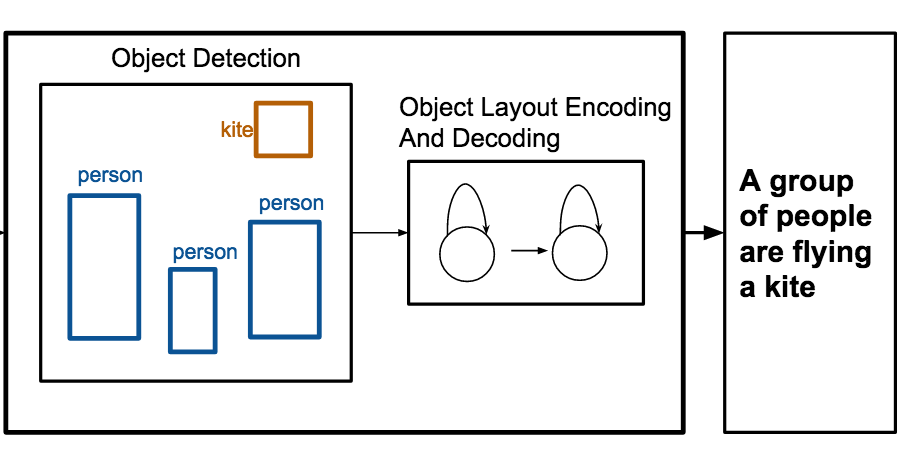
バージニア大学の研究者らは、生のピクセルデータを必要とせず、画像内のオブジェクトとその位置のリストだけを用いてシーンを記述するキャプションを自動的に書けるシステムを構築した。OBJ2TEXTと呼ばれるこのシステムは、オブジェクトのラベルとそのバウンディングボックスの座標を、レイアウトを系列としてエンコードする1つ目のニューラルネットワークに入力し、そのエンコードされた表現を、単語を1つずつ生成する2つ目のニューラルネットワークに渡すことで機能する。標準的なMS-COCO画像データセットでの検証により、研究チームは、オブジェクトの位置とオブジェクトの数の両方がキャプションの品質を意味のある形で向上させること(いずれか一方を取り除くと測定可能な性能低下が生じた)を見いだし、空間情報を系列的にエンコードしたものでさえ、実際の記述的価値を有することを実証した。おそらくより実用的なのは、研究者らがOBJ2TEXTをYOLOと呼ばれる物体検出器および従来の画像ベースのキャプショニングモデルと組み合わせたとき、このハイブリッドシステムが画像のみのキャプショニングのベースラインを上回り、MS-COCOベンチマークでCIDErスコアを0.863から0.950へと押し上げた点である。また、人間の評価者は、全員の意見が一致したとき、組み合わせたシステムのキャプションをおよそ65パーセントの割合で好んだ。シーンに関する構造化された記号的情報(物体検出器によって生成される類のもの、あるいはグラフィックデザインや絵コンテで用いられるもの)が、言語生成においてピクセルレベルの視覚的特徴を補完し、部分的にさえ代替しうることを示し、画像キャプショニングモデルがシーンについて実際に何を知る必要があるのかを研究するためのよりすっきりした方法を提供する点で、この研究は意義深い。
要旨
画像に対するキャプション生成は、近年大きな注目を集めているタスクである。本研究では、抽象的なシーン、すなわち提供される情報がオブジェクトの集合とその位置のみであるオブジェクトレイアウトに対するキャプション生成に焦点を当てる。我々は、LSTMネットワークを用いてオブジェクトの集合とその位置を入力系列としてエンコードし、その表現をLSTM言語モデルを用いてデコードする系列変換(sequence-to-sequence)モデルOBJ2TEXTを提案する。我々のモデルは、オブジェクトレイアウトを系列としてエンコードするにもかかわらず、オブジェクト間の空間的関係を表現でき、全体として一貫性があり意味的に関連性のある記述を生成できることを示す。オブジェクトのアノテーションのみを入力として用いるオブジェクトレイアウトキャプショニングのタスクで我々のアプローチを検証する。さらに、我々のモデルを最先端の物体検出器と組み合わせることで、標準的なMS-COCOキャプショニングタスクのテストベンチマークにおいて、画像キャプショニングモデルを0.863から0.950(CIDErスコア)に改善することを示す。
詳細
引用
@inproceedings{yin2017obj,
title = {Obj2Text: Generating Visually Descriptive Language from Object Layouts},
author = {Yin, Xuwang and Ordonez, Vicente},
year = {2017},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2017},
url = {https://arxiv.org/abs/1707.07102},
}