新闻稿摘要
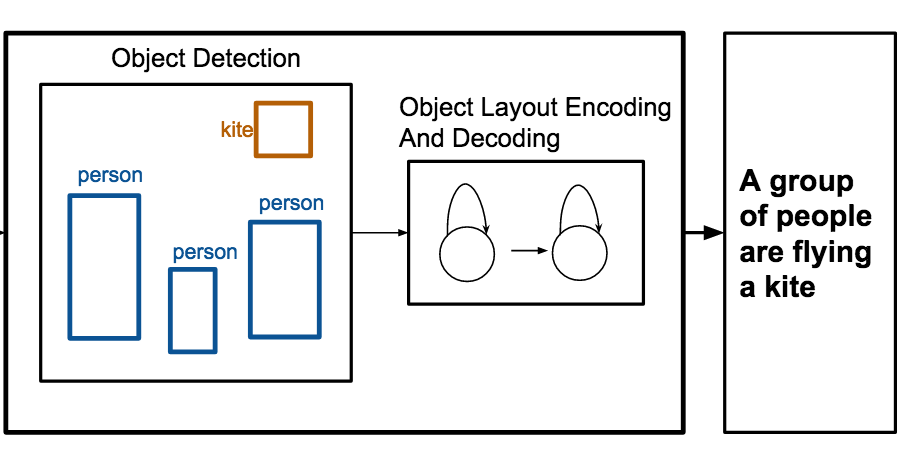
弗吉尼亚大学的研究人员构建了一个系统,它能仅凭一张物体及其在图像中位置的列表,自动撰写描述场景的标题,绕开了对原始像素数据的需求。该系统名为 OBJ2TEXT,其工作方式是将物体标签及其边界框坐标馈入一个将布局编码为序列的神经网络,然后将编码后的表示传递给第二个神经网络,由其逐词生成句子。在标准 MS-COCO 图像数据集上测试时,团队发现物体位置和物体数量都显著改善了标题质量——移除其中任何一个都会导致可测量的性能下降——表明即便是对空间信息的序列化编码也携带着真实的描述价值。或许更具实用性的是,当研究人员将 OBJ2TEXT 与一个名为 YOLO 的目标检测器以及一个传统的基于图像的描述模型相结合时,这一混合系统超越了仅基于图像的描述基线,在 MS-COCO 基准上将其 CIDEr 分数从 0.863 推升到 0.950;当人类评估者意见一致时,他们大约 65% 的情况下也更偏爱该组合系统的标题。这项工作的意义在于,它表明关于场景的结构化、符号化信息——由目标检测器产生的、或用于平面设计和故事板的那类信息——能够补充甚至部分替代语言生成中像素级的视觉特征,为研究图像描述模型究竟需要了解场景的哪些内容提供了一种更清晰的方式。
摘要
为图像生成描述是近来受到相当关注的一项任务。在这项工作中,我们聚焦于为抽象场景(即物体布局,其中提供的唯一信息是一组物体及其位置)生成描述。我们提出 OBJ2TEXT,一个序列到序列模型,它使用 LSTM 网络将一组物体及其位置编码为输入序列,并使用 LSTM 语言模型对该表示进行解码。我们表明,我们的模型尽管将物体布局编码为序列,仍能表示物体之间的空间关系,并生成全局连贯且语义相关的描述。我们在一项仅使用物体标注作为输入的物体布局描述任务中检验了我们的方法。我们还表明,我们的模型与一个最先进的目标检测器相结合,在标准 MS-COCO Captioning 任务的测试基准上将图像描述模型从 0.863 提升到 0.950(CIDEr 分数)。
详情
引用
@inproceedings{yin2017obj,
title = {Obj2Text: Generating Visually Descriptive Language from Object Layouts},
author = {Yin, Xuwang and Ordonez, Vicente},
year = {2017},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2017},
url = {https://arxiv.org/abs/1707.07102},
}