Going Beyond Nouns With Vision & Language Models Using Synthetic Data
Résumé du communiqué de presse
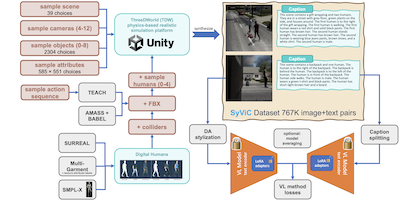
Des chercheurs du MIT, d'IBM, de Rice University et de plusieurs autres institutions ont identifié et franchi une étape pratique vers la correction d'un angle mort persistant dans des modèles vision-langage d'IA populaires comme CLIP : ces systèmes sont étonnamment mauvais pour comprendre quoi que ce soit au-delà des objets présents dans une image, peinant à saisir les attributs, les relations spatiales, les actions et l'ordre des mots d'une manière que les humains trouvent triviale. Pour remédier à cela, l'équipe a constitué un jeu de données synthétique d'un million d'images appelé SyViC — Synthetic Visual Concepts — en exécutant des simulations 3D fondées sur la physique dans le moteur ThreeDWorld, en peuplant des scènes d'objets, de matériaux et d'avatars humains animés vêtus de tenues variées, choisis aléatoirement, puis en générant automatiquement des légendes textuelles détaillées à partir des métadonnées de la scène. L'idée clé est que les environnements synthétiques permettent aux chercheurs de créer à faible coût des paires image-texte qui mettent délibérément en évidence les concepts non nominaux précis que les modèles manquent, ce qui serait d'une difficulté et d'un coût prohibitifs à réaliser avec des photographies du monde réel. Lorsqu'ils ont affiné CLIP et CyCLIP sur SyViC à l'aide d'une combinaison d'adaptation de paramètres de bas rang (LoRA), d'adaptation de domaine par transfert de style et d'une technique de fractionnement des légendes pour gérer des textes descriptifs plus longs, les modèles se sont améliorés jusqu'à 9,9% sur le banc d'essai de raisonnement compositionnel ARO et de 4,3% sur l'évaluation VL-Checklist, tout en sacrifiant moins de un pour cent de leur précision de classification zero-shot sur 21 tâches. Ce travail est important car il démontre que des données synthétiques ciblées, sans aucune image réelle, peuvent corriger de manière significative une faiblesse structurelle bien documentée de l'entraînement vision-langage contrastif, et l'équipe a rendu publics à la fois le jeu de données et le code.
résumé
Les modèles vision-langage (VL) pré-entraînés à grande échelle ont affiché des performances remarquables dans de nombreuses applications, permettant de remplacer un ensemble fixe de classes prises en charge par un raisonnement zero-shot à vocabulaire ouvert sur des invites en langage naturel (presque arbitraires). Cependant, des travaux récents ont mis au jour une faiblesse fondamentale de ces modèles. Par exemple, leur difficulté à comprendre les concepts du langage visuel (Visual Language Concepts, VLC) qui vont « au-delà des noms », comme le sens des mots non liés à des objets (par exemple les attributs, les actions, les relations, les états, etc.), ou leur difficulté à effectuer un raisonnement compositionnel, comme comprendre l'importance de l'ordre des mots dans une phrase. Dans ce travail, nous étudions dans quelle mesure des données purement synthétiques pourraient être exploitées pour apprendre à ces modèles à surmonter ces lacunes sans compromettre leurs capacités zero-shot. Nous proposons Synthetic Visual Concepts (SyViC) — un jeu de données synthétique à l'échelle du million et une base de code de génération de données permettant de produire des données supplémentaires appropriées pour améliorer la compréhension des VLC et le raisonnement compositionnel des modèles VL. De plus, nous proposons une stratégie générale d'affinage VL pour exploiter efficacement SyViC en vue d'atteindre ces améliorations. Nos expériences et études d'ablation approfondies sur les bancs d'essai VL-Checklist, Winoground et ARO démontrent qu'il est possible d'adapter de puissants modèles VL pré-entraînés avec des données synthétiques en améliorant significativement leur compréhension des VLC (par exemple de 9,9% sur ARO et de 4,3% sur VL-Checklist) avec une baisse inférieure à 1% de leur précision zero-shot.
détails
citation
@inproceedings{cascantebonilla2023going,
title = {Going Beyond Nouns With Vision & Language Models Using Synthetic Data},
author = {Cascante-Bonilla, Paola and Shehada, Khaled and Smith, James Seale and Doveh, Sivan and Kim, Donghyun and Panda, Rameswar and Varol, Gül and Oliva, Aude and Ordonez, Vicente and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {International Conference on Computer Vision. ICCV 2023},
url = {https://arxiv.org/abs/2303.17590},
}