Going Beyond Nouns With Vision & Language Models Using Synthetic Data
新闻稿摘要
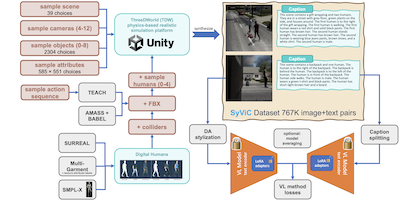
来自 MIT、IBM、莱斯大学及其他若干机构的研究人员识别出并朝着修复 CLIP 等流行 AI 视觉语言模型中一个持续存在的盲点迈出了实际一步:这些系统在理解图像中物体之外的任何东西时出人意料地糟糕,难以掌握属性、空间关系、动作和词序,而这些对人类而言却轻而易举。为解决这一问题,团队构建了一个百万图像规模的合成数据集,名为 SyViC(Synthetic Visual Concepts),方法是在 ThreeDWorld 引擎中运行基于物理的三维仿真,用随机化的物体、材质以及身着多样服装的动画人类化身填充场景,然后从场景元数据自动生成详细的文本描述。其关键洞见在于,合成环境使研究人员能够廉价地创建图像-文本对,这些数据对刻意凸显出模型所忽略的那些恰恰是非名词的概念,而用真实世界的照片来做这件事代价极高、难以实现。当他们结合使用低秩参数适配(LoRA)、基于风格迁移的领域适配以及一种处理较长描述文本的描述拆分技术,在 SyViC 上微调 CLIP 和 CyCLIP 时,模型在 ARO 组合推理基准上最高提升了 9.9%,在 VL-Checklist 评估上提升了 4.3%,而在 21 个任务上牺牲的零样本分类准确率不到百分之一。这项工作的意义在于,它证明了针对性的合成数据在不使用任何真实图像的情况下,能够显著修补对比式视觉语言训练中一个有充分记录的结构性弱点,并且团队已公开发布了数据集和代码。
摘要
大规模预训练视觉语言(VL)模型在众多应用中展现出非凡的性能,能够用对(几乎任意的)自然语言提示进行零样本开放词汇推理来替代固定的受支持类别集合。然而,近期研究揭示了这些模型的一个根本性弱点。例如,它们难以理解“超越名词”的视觉语言概念(VLC),如非物体词(如属性、动作、关系、状态等)的含义,或难以执行组合推理,如理解句子中词序的重要性。在这项工作中,我们研究在多大程度上可以利用纯合成数据来教这些模型克服此类不足,同时不损害其零样本能力。我们贡献了 Synthetic Visual Concepts(SyViC)——一个百万规模的合成数据集和数据生成代码库,允许生成额外的合适数据以改善 VL 模型的 VLC 理解和组合推理。此外,我们提出一种通用的 VL 微调策略,以有效利用 SyViC 来实现这些改进。我们在 VL-Checklist、Winoground 和 ARO 基准上进行的大量实验和消融表明,可以用合成数据来适配强大的预训练 VL 模型,显著增强其 VLC 理解(如在 ARO 上提升 9.9%、在 VL-Checklist 上提升 4.3%),而零样本准确率下降不到 1%。
详情
引用
@inproceedings{cascantebonilla2023going,
title = {Going Beyond Nouns With Vision & Language Models Using Synthetic Data},
author = {Cascante-Bonilla, Paola and Shehada, Khaled and Smith, James Seale and Doveh, Sivan and Kim, Donghyun and Panda, Rameswar and Varol, Gül and Oliva, Aude and Ordonez, Vicente and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {International Conference on Computer Vision. ICCV 2023},
url = {https://arxiv.org/abs/2303.17590},
}