Going Beyond Nouns With Vision & Language Models Using Synthetic Data
Resumo do comunicado de imprensa
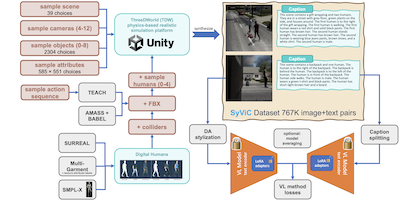
Pesquisadores do MIT, da IBM, da Rice University e de várias outras instituições identificaram e deram um passo prático rumo à correção de um ponto cego persistente em populares modelos de IA de visão e linguagem como o CLIP: esses sistemas são surpreendentemente ruins em entender qualquer coisa além dos objetos em uma imagem, tendo dificuldade em captar atributos, relações espaciais, ações e ordem das palavras de maneiras que os humanos consideram triviais. Para abordar isso, a equipe construiu um conjunto de dados sintético de um milhão de imagens chamado SyViC — Synthetic Visual Concepts — executando simulações 3D baseadas em física no motor ThreeDWorld, povoando cenas com objetos, materiais e avatares humanos animados aleatorizados vestidos com roupas diversas, e então gerando automaticamente legendas de texto detalhadas a partir dos metadados da cena. A percepção central é que ambientes sintéticos permitem que os pesquisadores criem de forma barata pares imagem-texto que destacam deliberadamente exatamente os conceitos não substantivos que os modelos não captam, algo que é proibitivamente difícil e caro de fazer com fotografias do mundo real. Ao ajustarem finamente o CLIP e o CyCLIP no SyViC usando uma combinação de adaptação de parâmetros de baixo posto (LoRA), adaptação de domínio baseada em transferência de estilo e uma técnica de divisão de legendas para lidar com textos descritivos mais longos, os modelos melhoraram em até 9,9% no benchmark de raciocínio composicional ARO e 4,3% na avaliação VL-Checklist, ao mesmo tempo em que sacrificaram menos de um por cento de sua acurácia de classificação zero-shot em 21 tarefas. O trabalho é importante porque demonstra que dados sintéticos direcionados, sem nenhuma imagem real, podem corrigir de maneira significativa uma fraqueza estrutural bem documentada no treinamento contrastivo de visão e linguagem, e a equipe disponibilizou publicamente tanto o conjunto de dados quanto o código.
resumo
Modelos de Visão e Linguagem (VL) pré-treinados em larga escala têm mostrado desempenho notável em muitas aplicações, possibilitando substituir um conjunto fixo de classes suportadas por raciocínio de vocabulário aberto zero-shot sobre prompts em linguagem natural (quase arbitrários). No entanto, trabalhos recentes revelaram uma fraqueza fundamental desses modelos. Por exemplo, sua dificuldade em entender Conceitos de Linguagem Visual (VLC) que vão 'além dos substantivos', como o significado de palavras não relacionadas a objetos (por exemplo, atributos, ações, relações, estados, etc.), ou a dificuldade em realizar raciocínio composicional, como compreender a importância da ordem das palavras em uma frase. Neste trabalho, investigamos em que medida dados puramente sintéticos poderiam ser aproveitados para ensinar esses modelos a superar tais deficiências sem comprometer suas capacidades zero-shot. Contribuímos com os Synthetic Visual Concepts (SyViC) - um conjunto de dados sintético em escala de milhões e uma base de código de geração de dados que permite gerar dados adicionais adequados para melhorar a compreensão de VLC e o raciocínio composicional de modelos de VL. Além disso, propomos uma estratégia geral de ajuste fino de VL para aproveitar efetivamente o SyViC visando alcançar essas melhorias. Nossos extensos experimentos e ablações nos benchmarks VL-Checklist, Winoground e ARO demonstram que é possível adaptar fortes modelos de VL pré-treinados com dados sintéticos, melhorando significativamente sua compreensão de VLC (por exemplo, em 9,9% no ARO e 4,3% no VL-Checklist) com menos de 1% de queda em sua acurácia zero-shot.
detalhes
citação
@inproceedings{cascantebonilla2023going,
title = {Going Beyond Nouns With Vision & Language Models Using Synthetic Data},
author = {Cascante-Bonilla, Paola and Shehada, Khaled and Smith, James Seale and Doveh, Sivan and Kim, Donghyun and Panda, Rameswar and Varol, Gül and Oliva, Aude and Ordonez, Vicente and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {International Conference on Computer Vision. ICCV 2023},
url = {https://arxiv.org/abs/2303.17590},
}