Going Beyond Nouns With Vision & Language Models Using Synthetic Data
Sintesi del comunicato stampa
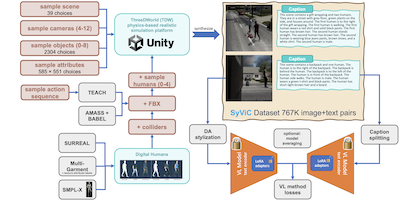
I ricercatori del MIT, di IBM, della Rice University e di diverse altre istituzioni hanno individuato e compiuto un passo pratico verso la correzione di un persistente punto cieco nei popolari modelli di IA vision-language come CLIP: questi sistemi sono sorprendentemente scarsi nel comprendere qualsiasi cosa al di là degli oggetti presenti in un'immagine, faticando a cogliere attributi, relazioni spaziali, azioni e l'ordine delle parole in modi che gli esseri umani trovano banali. Per affrontare questo problema, il team ha costruito un dataset sintetico da un milione di immagini chiamato SyViC — Synthetic Visual Concepts — eseguendo simulazioni 3D basate sulla fisica nel motore ThreeDWorld, popolando le scene con oggetti, materiali e avatar umani animati vestiti con abiti diversi, generati in modo casuale, per poi generare automaticamente didascalie testuali dettagliate a partire dai metadati della scena. L'intuizione chiave è che gli ambienti sintetici consentono ai ricercatori di creare a basso costo coppie immagine-testo che evidenziano deliberatamente proprio i concetti non riferiti a oggetti che i modelli non colgono, qualcosa che è proibitivamente difficile e costoso da fare con fotografie del mondo reale. Quando hanno sottoposto a fine-tuning CLIP e CyCLIP su SyViC utilizzando una combinazione di adattamento dei parametri a basso rango (LoRA), adattamento del dominio basato sul trasferimento di stile e una tecnica di suddivisione delle didascalie per gestire testi descrittivi più lunghi, i modelli sono migliorati fino al 9.9% sul benchmark di ragionamento composizionale ARO e del 4.3% sulla valutazione VL-Checklist, sacrificando al contempo meno dell'uno percento della loro accuratezza di classificazione zero-shot su 21 task. Il lavoro è importante perché dimostra che dati sintetici mirati, senza alcuna immagine reale, possono correggere in modo significativo una debolezza strutturale ben documentata dell'addestramento vision-language contrastive, e il team ha rilasciato pubblicamente sia il dataset sia il codice.
abstract
I modelli Vision & Language (VL) preaddestrati su larga scala hanno mostrato prestazioni notevoli in molte applicazioni, consentendo di sostituire un insieme fisso di classi supportate con un ragionamento zero-shot a vocabolario aperto su prompt in linguaggio naturale (quasi arbitrari). Tuttavia, lavori recenti hanno scoperto una debolezza fondamentale di questi modelli. Ad esempio, la loro difficoltà a comprendere i Visual Language Concepts (VLC) che vanno 'oltre i nomi', come il significato di parole non riferite a oggetti (ad es. attributi, azioni, relazioni, stati, ecc.), oppure la difficoltà a svolgere ragionamenti composizionali, come comprendere l'importanza dell'ordine delle parole in una frase. In questo lavoro, indaghiamo in che misura dati puramente sintetici possano essere sfruttati per insegnare a questi modelli a superare tali carenze senza compromettere le loro capacità zero-shot. Contribuiamo con Synthetic Visual Concepts (SyViC) — un dataset sintetico su scala di milioni e una codebase per la generazione di dati che consente di generare ulteriori dati adatti a migliorare la comprensione dei VLC e il ragionamento composizionale dei modelli VL. Inoltre, proponiamo una strategia generale di finetuning VL per sfruttare efficacemente SyViC al fine di ottenere questi miglioramenti. I nostri ampi esperimenti e le nostre ablation sui benchmark VL-Checklist, Winoground e ARO dimostrano che è possibile adattare potenti modelli VL preaddestrati con dati sintetici migliorando significativamente la loro comprensione dei VLC (ad es. del 9.9% su ARO e del 4.3% su VL-Checklist) con un calo inferiore all'1% della loro accuratezza zero-shot.
dettagli
citazione
@inproceedings{cascantebonilla2023going,
title = {Going Beyond Nouns With Vision & Language Models Using Synthetic Data},
author = {Cascante-Bonilla, Paola and Shehada, Khaled and Smith, James Seale and Doveh, Sivan and Kim, Donghyun and Panda, Rameswar and Varol, Gül and Oliva, Aude and Ordonez, Vicente and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {International Conference on Computer Vision. ICCV 2023},
url = {https://arxiv.org/abs/2303.17590},
}