Going Beyond Nouns With Vision & Language Models Using Synthetic Data
Tóm tắt thông cáo báo chí
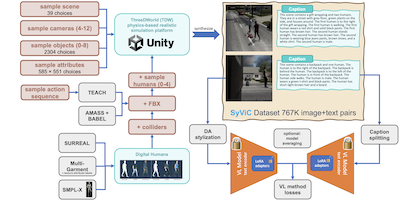
Các nhà nghiên cứu từ MIT, IBM, Rice University, và một số tổ chức khác đã xác định và tiến một bước thực tiễn hướng tới việc khắc phục một điểm mù dai dẳng trong các mô hình thị giác-ngôn ngữ phổ biến như CLIP: các hệ thống này tệ một cách đáng ngạc nhiên trong việc hiểu bất cứ điều gì vượt ra ngoài các đối tượng trong một ảnh, vật lộn để nắm bắt các thuộc tính, quan hệ không gian, hành động, và thứ tự từ theo những cách mà con người thấy là chuyện vặt. Để giải quyết điều này, nhóm nghiên cứu xây dựng một tập dữ liệu tổng hợp một triệu ảnh tên là SyViC — Synthetic Visual Concepts — bằng cách chạy các mô phỏng 3D dựa trên vật lý trong engine ThreeDWorld, lấp đầy các cảnh bằng các đối tượng, vật liệu được ngẫu nhiên hóa và các avatar người được tạo hoạt hình mặc quần áo đa dạng, rồi tự động sinh các chú thích văn bản chi tiết từ siêu dữ liệu của cảnh. Hiểu biết then chốt là các môi trường tổng hợp cho phép các nhà nghiên cứu tạo ra một cách rẻ tiền các cặp ảnh-văn bản cố ý làm nổi bật chính xác những khái niệm không-phải-danh-từ mà các mô hình bỏ lỡ, điều mà cực kỳ khó và đắt đỏ để thực hiện với các bức ảnh thực tế. Khi họ tinh chỉnh CLIP và CyCLIP trên SyViC bằng cách kết hợp thích ứng tham số hạng thấp (LoRA), thích ứng miền dựa trên chuyển đổi phong cách, và một kỹ thuật tách chú thích để xử lý văn bản mô tả dài hơn, các mô hình cải thiện tới 9.9% trên benchmark suy luận tổ hợp ARO và 4.3% trên đánh giá VL-Checklist, trong khi hy sinh chưa đến một phần trăm độ chính xác phân loại zero-shot của chúng trên 21 tác vụ. Công trình này quan trọng vì nó chứng minh rằng dữ liệu tổng hợp được nhắm trúng đích, không cần bất kỳ ảnh thực nào, có thể vá một cách có ý nghĩa một điểm yếu cấu trúc đã được ghi nhận rõ trong huấn luyện thị giác-ngôn ngữ tương phản, và nhóm nghiên cứu đã phát hành công khai cả tập dữ liệu lẫn mã nguồn.
tóm tắt
Các mô hình Thị giác & Ngôn ngữ (VL) được tiền huấn luyện quy mô lớn đã cho thấy hiệu năng đáng chú ý trong nhiều ứng dụng, cho phép thay thế một tập lớp được hỗ trợ cố định bằng suy luận zero-shot từ vựng mở trên (hầu như tùy ý) các prompt ngôn ngữ tự nhiên. Tuy nhiên, các công trình gần đây đã phát hiện ra một điểm yếu cơ bản của những mô hình này. Ví dụ, chúng khó hiểu các Khái niệm Ngôn ngữ Thị giác (VLC) đi 'vượt ra ngoài danh từ' như ý nghĩa của các từ không chỉ đối tượng (ví dụ, thuộc tính, hành động, quan hệ, trạng thái, v.v.), hoặc khó thực hiện suy luận tổ hợp như hiểu được tầm quan trọng của thứ tự các từ trong một câu. Trong công trình này, chúng tôi nghiên cứu xem dữ liệu thuần túy tổng hợp có thể được tận dụng đến mức nào để dạy những mô hình này vượt qua các thiếu sót đó mà không làm tổn hại đến khả năng zero-shot của chúng. Chúng tôi đóng góp Synthetic Visual Concepts (SyViC) - một tập dữ liệu tổng hợp quy mô triệu và một codebase sinh dữ liệu cho phép tạo thêm dữ liệu phù hợp để cải thiện khả năng hiểu VLC và suy luận tổ hợp của các mô hình VL. Ngoài ra, chúng tôi đề xuất một chiến lược tinh chỉnh VL tổng quát để tận dụng hiệu quả SyViC nhằm đạt được những cải thiện này. Các thí nghiệm và phân tích loại bỏ rộng rãi của chúng tôi trên các benchmark VL-Checklist, Winoground, và ARO minh chứng rằng có thể điều chỉnh các mô hình VL được tiền huấn luyện mạnh bằng dữ liệu tổng hợp để nâng cao đáng kể khả năng hiểu VLC của chúng (ví dụ 9.9% trên ARO và 4.3% trên VL-Checklist) với mức giảm dưới 1% về độ chính xác zero-shot.
chi tiết
trích dẫn
@inproceedings{cascantebonilla2023going,
title = {Going Beyond Nouns With Vision & Language Models Using Synthetic Data},
author = {Cascante-Bonilla, Paola and Shehada, Khaled and Smith, James Seale and Doveh, Sivan and Kim, Donghyun and Panda, Rameswar and Varol, Gül and Oliva, Aude and Ordonez, Vicente and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {International Conference on Computer Vision. ICCV 2023},
url = {https://arxiv.org/abs/2303.17590},
}