Commonly Uncommon: Semantic Sparsity in Situation Recognition
Résumé du communiqué de presse
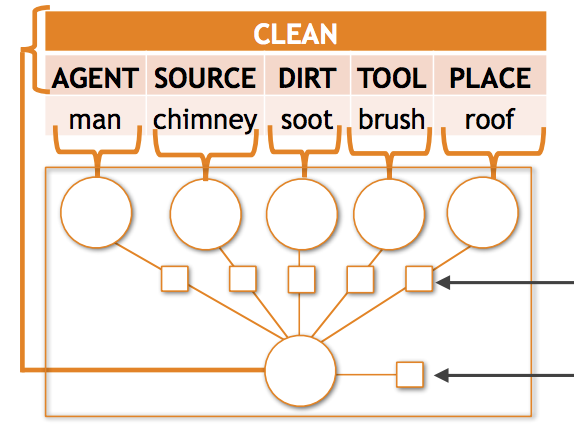
Des chercheurs de l'Université de Washington et de l'Allen Institute for Artificial Intelligence se sont attaqués à un problème tenace en vision par ordinateur : lorsque les systèmes d'IA tentent de décrire de manière structurée et détaillée ce qui se passe dans une photo — en identifiant non seulement une activité comme « porter », mais aussi qui porte, ce qui est porté et où — ils ont tendance à échouer dès que la scène implique une combinaison inhabituelle d'objets et de rôles. L'équipe a constaté que, dans le jeu de données de référence imSitu, environ 35 pour cent des prédictions requises impliquent des appariements objet-rôle vus moins de dix fois durant l'entraînement, et que les modèles existants perdent une précision significative précisément dans ces cas. Pour y remédier, les chercheurs ont mis au point deux techniques complémentaires. Premièrement, ils ont conçu un nouveau modèle mathématique appelé potentiel tensoriel compositionnel, intégré dans un cadre de champ aléatoire conditionnel (CRF), qui apprend des représentations partagées des noms à travers différents rôles — de sorte que la connaissance de l'apparence d'un « bébé », par exemple, puisse informer les prédictions, que le bébé apparaisse comme l'objet porté ou comme la personne qui porte. Deuxièmement, ils ont construit un pipeline d'augmentation sémantique des données qui convertit les situations d'entraînement annotées en courtes expressions textuelles, utilise ces expressions pour récupérer environ cinq millions d'images via la recherche d'images Google, et intègre les résultats bruités par un entraînement par vraisemblance marginale et par auto-apprentissage itératif. La combinaison des deux approches a amélioré la précision top-5 pour les verbes d'environ 6 pour cent et celle des rôles-noms de près de 10 pour cent par rapport à l'état de l'art antérieur, avec des gains relatifs encore plus importants sur les cas rares que ce travail vise spécifiquement. Ces résultats sont importants parce que la parcimonie sémantique — trop de combinaisons de sortie possibles, trop peu d'exemples pour la plupart d'entre elles — constitue un obstacle répandu dans les tâches de compréhension visuelle structurée, et ce travail offre une stratégie concrète et évolutive pour rendre les systèmes d'IA plus fiables face aux situations peu courantes qui, en pratique, sont assez fréquentes dans le monde réel.
résumé
La parcimonie sémantique est un défi courant dans les problèmes de classification visuelle structurée ; lorsque l'espace de sortie est complexe, la grande majorité des prédictions possibles sont rarement, voire jamais, observées dans l'ensemble d'entraînement. Cet article étudie la parcimonie sémantique dans la reconnaissance de situations, la tâche consistant à produire des résumés structurés de ce qui se passe dans les images, y compris les activités, les objets et les rôles que jouent les objets au sein de l'activité. Pour ce problème, nous constatons empiriquement que la plupart des combinaisons objet-rôle sont rares, et que les modèles actuels à l'état de l'art sous-performent de manière significative dans ce régime de données parcimonieuses. Nous évitons un grand nombre de ces erreurs en (1) introduisant une nouvelle fonction de composition tensorielle qui apprend à partager des exemples entre les combinaisons rôle-nom et (2) augmentant sémantiquement nos données d'entraînement avec des exemples, recueillis automatiquement à partir de données du web, de sorties rarement observées. Intégrée à un modèle complet de prédiction structurée fondé sur les CRF, l'approche fondée sur les tenseurs surpasse l'état de l'art existant avec une amélioration relative de 2,11 % et 4,40 % respectivement en précision top-5 pour les verbes et les rôles-noms. L'ajout de 5 millions d'images grâce à nos techniques d'augmentation sémantique apporte des améliorations relatives supplémentaires de 6,23 % et 9,57 % en précision top-5 pour les verbes et les rôles-noms.
citation
@inproceedings{yatskar2017commonly,
title = {Commonly Uncommon: Semantic Sparsity in Situation Recognition},
author = {Yatskar, Mark and Ordonez, Vicente and Zettlemoyer, Luke and Farhadi, Ali},
year = {2017},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2017},
url = {https://arxiv.org/abs/1612.00901},
}