Commonly Uncommon: Semantic Sparsity in Situation Recognition
Resumo do comunicado de imprensa
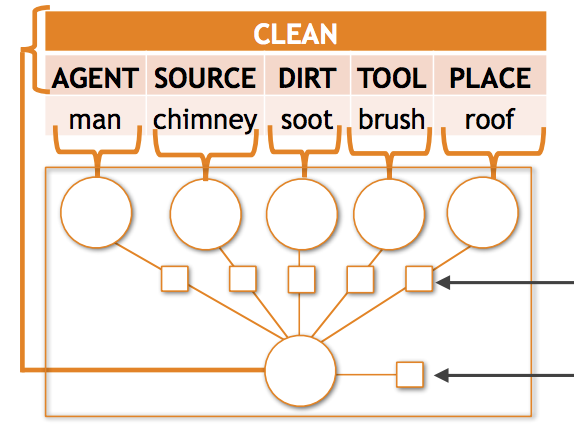
Pesquisadores da University of Washington e do Allen Institute for Artificial Intelligence enfrentaram um problema persistente em visão computacional: quando sistemas de IA tentam descrever o que está acontecendo em uma foto com detalhes estruturados — identificando não apenas uma atividade como "carregar", mas também quem está carregando, o que está sendo carregado e onde — eles tendem a falhar sempre que a cena envolve uma combinação incomum de objetos e papéis. A equipe constatou que, no conjunto de dados de benchmark imSitu, cerca de 35 por cento das previsões necessárias envolvem pareamentos objeto-papel vistos menos de dez vezes durante o treinamento, e os modelos existentes perdem precisão significativa exatamente nesses casos. Para resolver isso, os pesquisadores desenvolveram duas técnicas complementares. Primeiro, projetaram um novo modelo matemático chamado potencial tensorial composicional, incorporado a um framework de Campo Aleatório Condicional (CRF), que aprende representações compartilhadas de substantivos entre diferentes papéis — de modo que o conhecimento sobre a aparência de um "bebê", por exemplo, possa informar previsões independentemente de o bebê aparecer como a coisa sendo carregada ou a pessoa que está carregando. Segundo, construíram um pipeline de aumento semântico de dados que converte situações de treinamento anotadas em curtas frases de texto, usa essas frases para recuperar cerca de cinco milhões de imagens da busca de imagens do Google e incorpora os resultados ruidosos por meio de treinamento por verossimilhança marginal e autotreinamento iterativo. A combinação das duas abordagens melhorou a precisão top-5 de verbo em cerca de 6 por cento e a de papel-substantivo em quase 10 por cento em relação ao estado da arte anterior, com ganhos relativos ainda maiores nos casos raros que o trabalho especificamente visa. As descobertas são importantes porque a esparsidade semântica — combinações de saída possíveis demais, com exemplos de menos para a maioria delas — é um obstáculo generalizado em tarefas de compreensão visual estruturada, e este trabalho oferece uma estratégia concreta e escalável para tornar os sistemas de IA mais confiáveis ao se depararem com as situações incomuns que são, na prática, bastante comuns no mundo real.
resumo
A esparsidade semântica é um desafio comum em problemas de classificação visual estruturada; quando o espaço de saída é complexo, a grande maioria das previsões possíveis raramente, ou nunca, é vista no conjunto de treinamento. Este artigo estuda a esparsidade semântica no reconhecimento de situações, a tarefa de produzir resumos estruturados do que está acontecendo em imagens, incluindo atividades, objetos e os papéis que os objetos desempenham dentro da atividade. Para este problema, constatamos empiricamente que a maioria das combinações objeto-papel é rara, e os modelos de ponta atuais têm desempenho significativamente inferior neste regime de dados esparsos. Evitamos muitos desses erros ao (1) introduzir uma nova função de composição tensorial que aprende a compartilhar exemplos entre combinações papel-substantivo e (2) aumentar semanticamente nossos dados de treinamento com exemplos coletados automaticamente de saídas raramente observadas usando dados da web. Quando integrada a um modelo completo de predição estruturada baseado em CRF, a abordagem baseada em tensores supera o estado da arte existente com uma melhoria relativa de 2,11% e 4,40% na precisão top-5 de verbo e de papel-substantivo, respectivamente. Adicionar 5 milhões de imagens com nossas técnicas de aumento semântico proporciona melhorias relativas adicionais de 6,23% e 9,57% na precisão top-5 de verbo e de papel-substantivo.
citação
@inproceedings{yatskar2017commonly,
title = {Commonly Uncommon: Semantic Sparsity in Situation Recognition},
author = {Yatskar, Mark and Ordonez, Vicente and Zettlemoyer, Luke and Farhadi, Ali},
year = {2017},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2017},
url = {https://arxiv.org/abs/1612.00901},
}