Commonly Uncommon: Semantic Sparsity in Situation Recognition
Краткое изложение пресс-релиза
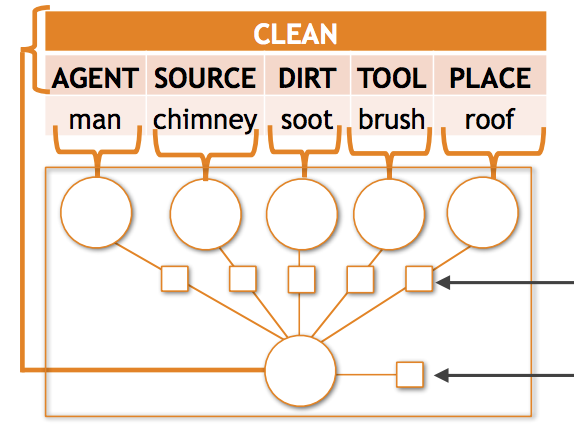
Исследователи из University of Washington и Allen Institute for Artificial Intelligence взялись за упорную проблему в компьютерном зрении: когда AI-системы пытаются описать происходящее на фотографии в структурированных деталях — идентифицируя не только активность вроде «несёт», но и кто несёт, что несёт и где — они склонны разваливаться всякий раз, когда сцена включает необычное сочетание объектов и ролей. Команда обнаружила, что в бенчмарк-наборе данных imSitu примерно 35 процентов требуемых предсказаний включают пары объект-роль, встречавшиеся при обучении менее десяти раз, и существующие модели значительно теряют точность именно в этих случаях. Чтобы решить это, исследователи разработали две дополняющие друг друга техники. Во-первых, они спроектировали новую математическую модель под названием композиционный тензорный потенциал, встроенную во фреймворк Conditional Random Field, которая учится разделяемым представлениям существительных между разными ролями — так что знание о том, как выглядит, например, «младенец», может информировать предсказания независимо от того, выступает ли младенец как то, что несут, или как тот, кто несёт. Во-вторых, они построили пайплайн семантической аугментации данных, который преобразует размеченные обучающие ситуации в короткие текстовые фразы, использует эти фразы для извлечения примерно пяти миллионов изображений из поиска по картинкам Google и включает зашумлённые результаты через обучение по маргинальному правдоподобию и итеративное самообучение. Сочетание обоих подходов улучшило точность top-5 для глаголов примерно на 6 процентов, а для роли-существительного — почти на 10 процентов по сравнению с предыдущим современным уровнем, с ещё большим относительным приростом на редких случаях, на которые работа специально нацелена. Выводы важны, поскольку семантическая разреженность — слишком много возможных сочетаний выходов, слишком мало примеров большинства из них — является широко распространённым препятствием в задачах структурированного визуального понимания, и эта работа предлагает конкретную, масштабируемую стратегию для повышения надёжности AI-систем при столкновении с нечастыми ситуациями, которые на практике довольно часты в реальном мире.
аннотация
Семантическая разреженность — распространённый вызов в задачах структурированной визуальной классификации; когда выходное пространство сложно, подавляющее большинство возможных предсказаний редко, если вообще когда-либо, встречаются в обучающем наборе. Эта статья изучает семантическую разреженность в распознавании ситуаций — задаче построения структурированных описаний того, что происходит на изображениях, включая активности, объекты и роли, которые объекты играют в рамках активности. Для этой задачи мы эмпирически обнаруживаем, что большинство сочетаний объект-роль редки, и современные модели значительно недорабатывают в этом режиме разреженных данных. Мы избегаем многих таких ошибок, (1) вводя новую функцию тензорной композиции, которая учится разделять примеры между сочетаниями роль-существительное, и (2) семантически дополняя наши обучающие данные автоматически собранными примерами редко наблюдаемых выходов с использованием веб-данных. При интеграции в полную модель структурированного предсказания на основе CRF подход на основе тензоров превосходит существующий современный уровень с относительным улучшением на 2,11% и 4,40% по точности top-5 для глаголов и для роли-существительного соответственно. Добавление 5 миллионов изображений с помощью наших техник семантической аугментации даёт дальнейшие относительные улучшения на 6,23% и 9,57% по точности top-5 для глаголов и для роли-существительного.
цитирование
@inproceedings{yatskar2017commonly,
title = {Commonly Uncommon: Semantic Sparsity in Situation Recognition},
author = {Yatskar, Mark and Ordonez, Vicente and Zettlemoyer, Luke and Farhadi, Ali},
year = {2017},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2017},
url = {https://arxiv.org/abs/1612.00901},
}