新闻稿摘要
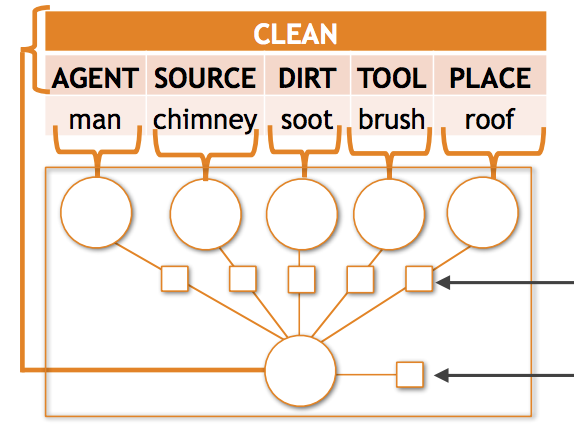
华盛顿大学和 Allen Institute for Artificial Intelligence 的研究人员攻克了计算机视觉中一个棘手的问题:当 AI 系统试图以结构化的细节描述一张照片中正在发生的事情时——不仅识别像“搬运”这样的活动,还要识别谁在搬运、搬运什么以及在哪里搬运——只要场景涉及物体和角色的不寻常组合,它们就往往会失灵。该团队发现,在 imSitu 基准数据集中,大约 35% 的必需预测涉及在训练期间出现不到十次的物体-角色配对,而现有模型恰恰在这些情况下损失了大量准确性。为解决这一问题,研究人员开发了两种互补的技术。首先,他们设计了一个名为组合式张量势(compositional tensor potential)的新数学模型,将其嵌入到 Conditional Random Field 框架中,该模型学习名词在不同角色之间的共享表示——例如,关于“婴儿”长什么样的知识,无论婴儿是作为被搬运的对象还是作为进行搬运的人出现,都可以为预测提供信息。其次,他们构建了一个语义数据增强流程,将带标注的训练情境转化为简短的文本短语,使用这些短语从 Google 图像搜索中检索约五百万张图像,并通过边际似然训练和迭代自训练纳入这些有噪声的结果。结合这两种方法,将 top-5 动词准确率提升了约 6%,名词-角色准确率提升了近 10%,超过了此前的最先进水平,而在该工作专门针对的罕见情况上,相对提升甚至更大。这些发现之所以重要,是因为语义稀疏性——可能的输出组合太多,而其中大多数的样本又太少——是结构化视觉理解任务中一个普遍存在的障碍,而这项工作为使 AI 系统在遇到那些不寻常但实际上相当常见的情况时变得更可靠,提供了一种具体、可扩展的策略。
摘要
语义稀疏性是结构化视觉分类问题中的一个常见挑战;当输出空间复杂时,绝大多数可能的预测在训练集中即便出现过也极为罕见。本文研究情境识别(situation recognition)中的语义稀疏性,该任务旨在生成图像中所发生事件的结构化摘要,包括活动、物体以及物体在活动中所扮演的角色。对于这个问题,我们通过实证发现,大多数物体-角色组合都很罕见,而当前最先进的模型在这种稀疏数据情形下表现明显不佳。我们通过以下方式避免许多此类错误:(1) 引入一种新颖的张量组合函数,它学会在角色-名词组合之间共享样本;(2) 使用从网络数据中自动收集的罕见输出样本对训练数据进行语义增强。当集成到一个完整的基于 CRF 的结构化预测模型中时,基于张量的方法在 top-5 动词和名词-角色准确率上分别以 2.11% 和 4.40% 的相对提升优于现有的最先进水平。通过我们的语义增强技术加入 500 万张图像,进一步在 top-5 动词和名词-角色准确率上带来了 6.23% 和 9.57% 的相对提升。
引用
@inproceedings{yatskar2017commonly,
title = {Commonly Uncommon: Semantic Sparsity in Situation Recognition},
author = {Yatskar, Mark and Ordonez, Vicente and Zettlemoyer, Luke and Farhadi, Ali},
year = {2017},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2017},
url = {https://arxiv.org/abs/1612.00901},
}