Commonly Uncommon: Semantic Sparsity in Situation Recognition
Sintesi del comunicato stampa
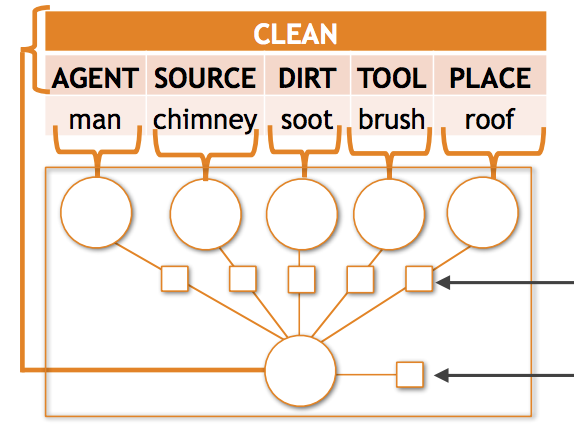
I ricercatori della University of Washington e dell'Allen Institute for Artificial Intelligence hanno affrontato un problema ostinato nella visione artificiale: quando i sistemi di IA cercano di descrivere ciò che accade in una foto con un dettaglio strutturato — identificando non solo un'attività come "trasportare", ma anche chi trasporta, cosa trasporta e dove — tendono a crollare ogni volta che la scena coinvolge una combinazione insolita di oggetti e ruoli. Il gruppo ha riscontrato che nel dataset di benchmark imSitu circa il 35 percento delle previsioni richieste riguarda abbinamenti oggetto-ruolo osservati meno di dieci volte durante l'addestramento, e che i modelli esistenti perdono un'accuratezza significativa proprio in questi casi. Per affrontare il problema, i ricercatori hanno sviluppato due tecniche complementari. In primo luogo, hanno progettato un nuovo modello matematico chiamato potenziale tensoriale composizionale, integrato all'interno di un framework di Conditional Random Field, che apprende rappresentazioni condivise dei sostantivi tra i diversi ruoli — così che la conoscenza dell'aspetto di un "bambino", ad esempio, possa informare le previsioni indipendentemente dal fatto che il bambino compaia come oggetto trasportato o come persona che effettua il trasporto. In secondo luogo, hanno costruito una pipeline di arricchimento semantico dei dati che converte le situazioni di addestramento annotate in brevi frasi testuali, le utilizza per recuperare circa cinque milioni di immagini dalla ricerca immagini di Google e incorpora i risultati rumorosi tramite addestramento a verosimiglianza marginale e self-training iterativo. La combinazione di entrambi gli approcci ha migliorato l'accuratezza top-5 sui verbi di circa il 6 percento e quella sui ruoli-sostantivo di quasi il 10 percento rispetto al precedente stato dell'arte, con guadagni relativi ancora maggiori sui casi rari specificamente presi di mira dal lavoro. I risultati sono importanti perché la sparsità semantica — troppe combinazioni di output possibili, troppo pochi esempi della maggior parte di esse — è un ostacolo diffuso nei compiti di comprensione visiva strutturata, e questo lavoro offre una strategia concreta e scalabile per rendere i sistemi di IA più affidabili di fronte alle situazioni non comuni che, nella pratica, sono piuttosto comuni nel mondo reale.
abstract
La sparsità semantica è una sfida comune nei problemi di classificazione visiva strutturata; quando lo spazio di output è complesso, la grande maggioranza delle previsioni possibili compare raramente, se non mai, nell'insieme di addestramento. Questo articolo studia la sparsità semantica nel riconoscimento delle situazioni, il compito di produrre riassunti strutturati di ciò che accade nelle immagini, comprese le attività, gli oggetti e i ruoli che gli oggetti svolgono all'interno dell'attività. Per questo problema, riscontriamo empiricamente che la maggior parte delle combinazioni oggetto-ruolo è rara e che i modelli attuali allo stato dell'arte hanno prestazioni significativamente inferiori in questo regime di dati sparsi. Evitiamo molti di tali errori (1) introducendo una nuova funzione di composizione tensoriale che impara a condividere esempi tra le combinazioni ruolo-sostantivo e (2) arricchendo semanticamente i nostri dati di addestramento con esempi raccolti automaticamente di output osservati raramente, utilizzando dati provenienti dal web. Quando integrato all'interno di un modello completo di predizione strutturata basato su CRF, l'approccio basato su tensori supera lo stato dell'arte esistente con un miglioramento relativo del 2,11% e del 4,40% rispettivamente nell'accuratezza top-5 sui verbi e sui ruoli-sostantivo. L'aggiunta di 5 milioni di immagini con le nostre tecniche di arricchimento semantico produce ulteriori miglioramenti relativi del 6,23% e del 9,57% nell'accuratezza top-5 sui verbi e sui ruoli-sostantivo.
citazione
@inproceedings{yatskar2017commonly,
title = {Commonly Uncommon: Semantic Sparsity in Situation Recognition},
author = {Yatskar, Mark and Ordonez, Vicente and Zettlemoyer, Luke and Farhadi, Ali},
year = {2017},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2017},
url = {https://arxiv.org/abs/1612.00901},
}