Going Beyond Nouns With Vision & Language Models Using Synthetic Data
Zusammenfassung der Pressemitteilung
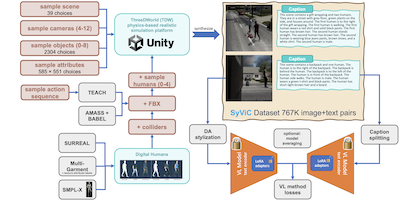
Forschende des MIT, von IBM, der Rice University und mehrerer weiterer Institutionen haben einen hartnäckigen blinden Fleck in beliebten KI-Vision-Language-Modellen wie CLIP identifiziert und einen praktischen Schritt zu dessen Behebung unternommen: Diese Systeme sind überraschend schlecht darin, irgendetwas jenseits der Objekte in einem Bild zu verstehen, und tun sich schwer, Attribute, räumliche Beziehungen, Handlungen und Wortreihenfolge auf eine Weise zu erfassen, die Menschen trivial erscheint. Um dem zu begegnen, baute das Team einen synthetischen Datensatz aus einer Million Bildern namens SyViC – Synthetic Visual Concepts –, indem es physikbasierte 3D-Simulationen in der ThreeDWorld-Engine ausführte, Szenen mit zufällig zusammengestellten Objekten, Materialien und animierten menschlichen Avataren in vielfältiger Kleidung füllte und anschließend automatisch detaillierte Textbeschreibungen aus den Szenenmetadaten erzeugte. Die zentrale Erkenntnis ist, dass synthetische Umgebungen es Forschenden ermöglichen, kostengünstig Bild-Text-Paare zu erstellen, die gezielt genau jene Nicht-Substantiv-Konzepte hervorheben, die den Modellen entgehen – etwas, das mit Fotografien aus der realen Welt unverhältnismäßig schwierig und teuer wäre. Als sie CLIP und CyCLIP auf SyViC mithilfe einer Kombination aus parametereffizienter Anpassung mit niedrigem Rang (LoRA), stiltransferbasierter Domänenanpassung und einer Technik zur Aufteilung von Bildunterschriften zur Verarbeitung längerer beschreibender Texte feinabstimmten, verbesserten sich die Modelle um bis zu 9,9 % auf dem ARO-Benchmark für kompositionelles Schlussfolgern und um 4,3 % auf der VL-Checklist-Auswertung, während sie über 21 Aufgaben hinweg weniger als ein Prozent ihrer Zero-Shot-Klassifikationsgenauigkeit einbüßten. Die Arbeit ist bedeutsam, weil sie zeigt, dass gezielte synthetische Daten ohne jegliche realen Bilder eine gut dokumentierte strukturelle Schwäche im kontrastiven Vision-Language-Training spürbar beheben können, und das Team hat sowohl den Datensatz als auch den Code öffentlich zugänglich gemacht.
Zusammenfassung
Großmaßstäblich vortrainierte Vision-&-Language-Modelle (VL) haben in vielen Anwendungen eine bemerkenswerte Leistung gezeigt und ermöglichen es, eine feste Menge unterstützter Klassen durch Zero-Shot-Schlussfolgerungen mit offenem Vokabular über (nahezu beliebige) natürlichsprachliche Prompts zu ersetzen. Jüngere Arbeiten haben jedoch eine grundlegende Schwäche dieser Modelle aufgedeckt. Beispielsweise fällt es ihnen schwer, visuelle Sprachkonzepte (Visual Language Concepts, VLC) zu verstehen, die "über Substantive hinausgehen", etwa die Bedeutung von Nicht-Objekt-Wörtern (z. B. Attribute, Handlungen, Relationen, Zustände usw.), oder kompositionelle Schlussfolgerungen anzustellen, etwa die Bedeutung der Reihenfolge der Wörter in einem Satz zu erfassen. In dieser Arbeit untersuchen wir, inwieweit rein synthetische Daten genutzt werden könnten, um diesen Modellen beizubringen, solche Defizite zu überwinden, ohne ihre Zero-Shot-Fähigkeiten zu beeinträchtigen. Wir steuern Synthetic Visual Concepts (SyViC) bei – einen synthetischen Datensatz im Millionenmaßstab samt einer Codebasis zur Datengenerierung, die es erlaubt, zusätzliche geeignete Daten zu erzeugen, um das VLC-Verständnis und die kompositionellen Schlussfolgerungen von VL-Modellen zu verbessern. Darüber hinaus schlagen wir eine allgemeine VL-Feintuning-Strategie vor, um SyViC wirksam zur Erzielung dieser Verbesserungen zu nutzen. Unsere umfangreichen Experimente und Ablationsstudien auf den Benchmarks VL-Checklist, Winoground und ARO zeigen, dass es möglich ist, starke vortrainierte VL-Modelle mit synthetischen Daten anzupassen und dabei ihr VLC-Verständnis erheblich zu verbessern (z. B. um 9,9 % auf ARO und 4,3 % auf VL-Checklist) bei einem Rückgang ihrer Zero-Shot-Genauigkeit von unter 1 %.
Details
Zitation
@inproceedings{cascantebonilla2023going,
title = {Going Beyond Nouns With Vision & Language Models Using Synthetic Data},
author = {Cascante-Bonilla, Paola and Shehada, Khaled and Smith, James Seale and Doveh, Sivan and Kim, Donghyun and Panda, Rameswar and Varol, Gül and Oliva, Aude and Ordonez, Vicente and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {International Conference on Computer Vision. ICCV 2023},
url = {https://arxiv.org/abs/2303.17590},
}