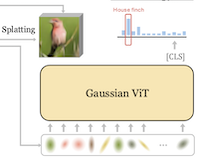
GViT: Representing Images as Gaussians for Visual Recognition
Zusammenfassung der Pressemitteilung
Forschende an der Rice University und der UC Irvine haben ein neues Bildklassifikationssystem entwickelt, das den konventionellen Ansatz aufgibt, einem neuronalen Netzwerk ein Raster aus Pixeln oder rechteckigen Patches zuzuführen, und diese Eingabe durch eine kompakte Menge mathematischer Klümpchen ersetzt, die als 2D-Gaußfunktionen bezeichnet werden. Das System namens GViT funktioniert, indem ein kleines Encoder-Netzwerk darauf trainiert wird, jedes Bild mithilfe einiger hundert Gaußfunktionen zu beschreiben, wobei jedes Klümpchen Informationen über seine Position, Größe, Orientierung, Farbe und Opazität trägt. Der raffinierte Teil des Trainingsaufbaus besteht darin, dass das Klassifikationsmodell und der Gauß-Encoder gemeinsam in einer Rückkopplungsschleife trainiert werden: Gradienten des Klassifikators – im Wesentlichen Signale darüber, welche Bildteile für die Identifikation des Inhalts von Bedeutung sind – werden zurückgespeist, um die Gaußfunktionen auf jene Regionen zu lenken, die tatsächlich für die Erkennung nützlich sind, statt sie gleichmäßig über uninformativen Hintergrund verteilen zu lassen. Mit diesem Ansatz erreichte die beste Version von GViT auf dem standardmäßigen ImageNet-1k-Benchmark eine Top-1-Genauigkeit von 76,9 % mit einer ViT-Base-Architektur, verglichen mit etwa 78,7 % für einen konventionellen patchbasierten ViT ähnlicher Größe – ein Abstand von weniger als zwei Prozentpunkten bei Verwendung einer grundlegend anderen und weit kompakteren Eingaberepräsentation. Die Arbeit ist von Bedeutung, nicht weil sie bestehende Systeme unmittelbar übertrifft, sondern weil sie zeigt, dass intermediäre, für Menschen interpretierbare geometrische Primitive eine wettbewerbsfähige visuelle Erkennung unterstützen können, und als Nebeneffekt neigen die erlernten Gaußfunktionen dazu, sich um jene Teile einer Szene zu gruppieren, die das Modell am unterscheidungskräftigsten findet, was eine leichtgewichtige Form der Erklärbarkeit bietet, die Pixelraster-Modelle nicht von Natur aus bereitstellen.
Zusammenfassung
Wir stellen GVIT vor, ein Klassifikations-Framework, das konventionelle Pixel- oder Patch-Raster-Eingaberepräsentationen zugunsten einer kompakten Menge erlernbarer 2D-Gaußfunktionen aufgibt. Jedes Bild wird als einige hundert Gaußfunktionen kodiert, deren Positionen, Skalen, Orientierungen, Farben und Opazitäten gemeinsam mit einem ViT-Klassifikator optimiert werden, der auf diesen Repräsentationen trainiert wird. Wir nutzen die Klassifikator-Gradienten als konstruktive Anleitung wieder und steuern die Gaußfunktionen auf klassen-saliente Regionen, während ein differenzierbarer Renderer einen Verlust für die Bildrekonstruktion optimiert. Wir zeigen, dass 2D-Gauß-Eingaberepräsentationen in Verbindung mit unserer GVIT-Anleitung unter Verwendung einer relativ standardmäßigen ViT-Architektur die Leistung eines traditionellen patchbasierten ViT eng erreichen und eine Top-1-Genauigkeit von 76,9 % auf Imagenet-1k mit einer ViT-B-Architektur erzielen.
Zitation
@article{hernandezgvit,
title = {GViT: Representing Images as Gaussians for Visual Recognition},
author = {Hernandez, Jefferson and He, Ruozhen and Balakrishnan, Guha and Berg, Alexander C. and Ordonez, Vicente},
journal = {arXiv preprint arXiv:2506.23532},
url = {https://arxiv.org/abs/2506.23532},
}
automatisch generierte Fragen, wichtigste Beiträge und Grenzen dieses Artikels
Fragen, die dieser Artikel beantworten hilft
- Was ist GViT und welches Problem adressiert es? GViT ist ein Framework zur visuellen Erkennung, das feste Pixel- oder Patch-Raster-Eingaben durch eine kompakte Menge erlernbarer 2D-Gauß-Primitive ersetzt und damit testet, ob geometrische Repräsentationen auf mittlerer Ebene eine wettbewerbsfähige Bildklassifikation unterstützen können.
- Wie werden die Gaußfunktionen erlernt? Ein entrauschender Gauß-Encoder sagt Gauß-Zentren, -Skalen, -Orientierungen, -Farben und -Opazitäten voraus, während ein differenzierbarer Renderer die Bildrekonstruktion optimiert und ein ViT-Klassifikator konstruktive Gradienten liefert, die die Gaußfunktionen auf klassen-saliente Regionen lenken.
- Wie gut schneidet GViT auf ImageNet-1k ab? Das geführte GViT-B-Modell erreicht 76,9 Prozent Top-1-Genauigkeit auf ImageNet-1k, nahe den für einen ähnlich großen patchbasierten ViT-B/16 berichteten 78,7 Prozent, während es eine wesentlich andere Gauß-Eingaberepräsentation verwendet.
- Warum ist die Anleitung durch Klassifikator-Gradienten wichtig? Die Arbeit berichtet, dass die Anleitung GViT-B auf ImageNet-1k von 73,6 Prozent auf 76,9 Prozent verbessert und kleinere Modelle in ähnlicher Weise verbessert, was zeigt, dass eine aufgabenbewusste Platzierung der Gaußfunktionen zentral dafür ist, die Repräsentation für die Erkennung nützlich zu machen.
- Bietet GViT Vorteile bei der Interpretierbarkeit? Ja, die erlernten Gauß-Kovarianzen und klassen-diskriminativen Attention-Maps neigen dazu, sich auf klassenrelevante Bildregionen zu konzentrieren, was der Repräsentation eine geometrische visuelle Erklärung verleiht, die standardmäßige Patch-Tokens nicht von Natur aus offenlegen.
Wichtigste Beiträge
- Die Arbeit führt eine ViT-kompatible Bildrepräsentation ein, die auf Mengen von 2D-Gauß-Primitiven statt auf Pixeln, Patches, rohen Bytes oder komprimierten Frequenzkoeffizienten basiert.
- GViT schlägt ein kooperatives Trainingsschema vor, bei dem Rekonstruktionsverluste die Bildtreue bewahren, während Klassifikator-Gradienten die Gaußfunktionen aktiv auf diskriminative visuelle Evidenz verlagern.
- Die ImageNet-1k-Experimente zeigen, dass Gauß-Eingaben mit einem ViT-B-Backbone 76,9 Prozent Top-1-Genauigkeit erreichen können, womit sie mehrere in der Arbeit aufgeführte Nicht-Patch-Eingabealternativen übertreffen und bis auf 1,8 Punkte an einen konventionellen patchbasierten ViT-B/16 herankommen.
- Ablationen auf Mini-ImageNet-100 zeigen, dass Entrauschen und Anleitung durch Klassifikator-Gradienten die Platzierung der Gaußfunktionen bedeutsam verbessern, wobei die vollständige geführte Version das Offline-Anpassen der Gaußfunktionen, erlernte Queries und ungeführtes Entrauschen übertrifft.
- Die Analyse zeigt, dass die Skala der Gaußfunktionen und die Attention-Signale mit klassen-diskriminativen Regionen übereinstimmen, was die Behauptung stützt, dass GViT eine kompakte Erkennungsrepräsentation mit einer natürlichen Interpretierbarkeitskomponente bietet.
Grenzen und Vorbehalte
- Patchbasierte ViTs bleiben für viele großmaßstäbliche Bereitstellungen heute die pragmatischste Wahl, doch der geringe Genauigkeitsabstand von GViT auf ImageNet-1k spricht stark dafür, dass Gauß-Primitive bereits eine tragfähige und überraschend wettbewerbsfähige alternative Repräsentation sind.
- Die Anzahl der Gaußfunktionen wird vor dem Training festgelegt, sodass künftige Versionen von dynamischem Erzeugen, Beschneiden oder Umverteilen profitieren könnten; die monotonen Gewinne, die mit steigendem Gauß-Budget beobachtet werden, liefern nützliche Hinweise für diesen nächsten Designschritt.
- Differenzierbares Rendering fügt Speicher- und Rechenaufwand hinzu, insbesondere bei hohen Auflösungen oder mit mehr als 512 Gaußfunktionen beim Training im ImageNet-Maßstab; dies ist ein Engineering-Engpass um eine ansonsten vielversprechende Repräsentation herum und keine Schwäche der Kernidee.
- Die Experimente konzentrieren sich auf Bildklassifikation und Transfer-Klassifikations-Benchmarks statt auf dichte Vorhersageaufgaben wie Detektion oder Segmentierung; die klassen-salienten Gauß-Anordnungen legen nahe, dass diese Aufgaben natürliche Orte sind, an denen die Repräsentation als Nächstes zu erkunden ist.
- Der aktuelle Ansatz komprimiert per Design einige feingranulare Pixeldetails heraus, was die Repräsentation kompakt und interpretierbar macht, während er Raum für künftige Arbeiten lässt, die Balance zwischen Rekonstruktionstreue und semantischer Unterscheidung abzustimmen.
Wie dieses Ergebnis zu lesen ist
Diese Arbeit ist am besten als ein starkes, durch Evidenz gestütztes Argument dafür zu lesen, dass visuelle Erkennung nicht an Pixel- oder Patch-Raster gebunden sein muss: GViT hält die ImageNet-Leistung nahe an standardmäßigen ViTs, während es eine interpretierbare Gauß-Repräsentation einführt, die eine vielversprechende Richtung für künftige Vision-Backbones eröffnet.