MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction
Zusammenfassung der Pressemitteilung
Forschende bei Meta und an der Rice University haben MetaEmbed entwickelt, einen neuen Ansatz für multimodale Suche, der es Systemen ermöglicht, ihre Genauigkeit und Geschwindigkeit nach Bedarf anzupassen. Aktuelle multimodale Retrieval-Systeme, die über Text und Bilder hinweg suchen, stehen vor einem Zielkonflikt zwischen Präzision und Recheneffizienz – sie komprimieren entweder alles in einen einzigen Vektor, der Details verliert, oder verwenden Hunderte von Vektoren, die für den praktischen Einsatz zu langsam werden. MetaEmbed führt erlernbare „Meta Tokens“ ein, die eine kleine Menge kontextualisierter Embeddings erzeugen, die von grob- zu feingranularen Informationen organisiert sind. Dieses Design ermöglicht es Nutzenden, zu wählen, wie viele Vektoren während der Suche verwendet werden, und so Qualität gegen Geschwindigkeitsanforderungen abzuwägen. Tests auf standardmäßigen Benchmarks zeigen, dass das System eine State-of-the-Art-Leistung erzielt, während es skaliert
Zusammenfassung
Universelle multimodale Embedding-Modelle haben großen Erfolg dabei erzielt, semantische Relevanz zwischen Anfragen und Kandidaten zu erfassen. Aktuelle Methoden verdichten jedoch entweder Anfragen und Kandidaten zu einem einzigen Vektor, was die Ausdruckskraft für feingranulare Informationen potenziell einschränkt, oder erzeugen zu viele Vektoren, die für die Multi-Vektor-Retrieval-Suche prohibitiv sind. In dieser Arbeit führen wir MetaEmbed ein, ein neues Framework für multimodales Retrieval, das neu durchdenkt, wie multimodale Embeddings im großen Maßstab konstruiert werden und wie mit ihnen interagiert wird. Während des Trainings wird eine feste Anzahl erlernbarer Meta Tokens an die Eingabesequenz angehängt. Zur Testzeit dienen ihre kontextualisierten Repräsentationen aus der letzten Schicht als kompakte und zugleich ausdrucksstarke Multi-Vektor-Embeddings. Durch das vorgeschlagene Matryoshka-Multi-Vector-Retrieval-Training lernt MetaEmbed, Informationen nach Granularität über mehrere Vektoren hinweg zu organisieren. Dadurch ermöglichen wir Test-Time-Scaling im multimodalen Retrieval, bei dem Nutzende die Retrieval-Qualität gegen Effizienzanforderungen abwägen können, indem sie die Anzahl der für Indexierung und Retrieval-Interaktionen verwendeten Tokens wählen. Umfangreiche Evaluationen auf dem Massive Multimodal Embedding Benchmark (MMEB) und dem Visual Document Retrieval Benchmark (ViDoRe) bestätigen, dass MetaEmbed eine State-of-the-Art-Retrieval-Leistung erzielt, während es robust auf Modelle mit 32B Parametern skaliert. Der Code ist verfügbar unter https://github.com/facebookresearch/MetaEmbed.
Details
Zitation
@inproceedings{xiao2026metaembed,
title = {MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction},
author = {Xiao, Zilin and Ma, Qi and Gu, Mengting and Chen, Chun-cheng Jason and Chen, Xintao and Ordonez, Vicente and Mohan, Vijai},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2509.18095},
}
automatisch generierte Fragen, wichtigste Beiträge und Grenzen dieses Artikels
Fragen, die dieser Artikel beantworten hilft
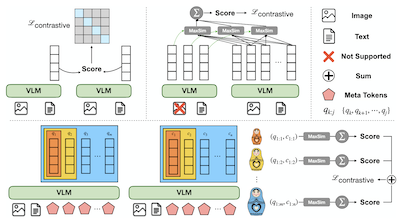
- Was ist MetaEmbed und welches Problem adressiert es? MetaEmbed ist ein Framework für multimodales Retrieval, das kompakte erlernbare Meta Tokens verwendet, um ein ausdrucksstärkeres Retrieval als Single-Vektor-Embeddings zu ermöglichen, ohne die hohen Kosten von Hunderten von Vektoren auf Patch-Ebene.
- Wie ermöglicht MetaEmbed Test-Time-Scaling? Es trainiert verschachtelte Gruppen von Meta Embeddings durch Matryoshka Multi-Vector Retrieval, sodass Nutzende kleinere oder größere Retrieval-Budgets zur Indexierungs- und Bewertungszeit ohne erneutes Training wählen können.
- Warum sind Meta Tokens für multimodales Retrieval nützlich? Ihre kontextualisierten Zustände aus der letzten Schicht wirken als kleine Menge von Multi-Vektor-Embeddings, die feingranulare Anfrage-Kandidat-Interaktionen bewahren, während die Indexgröße und die Bewertungskosten kontrollierbar bleiben.
- Wie gut schneidet MetaEmbed auf MMEB ab? Die Arbeit berichtet, dass das mit Qwen2.5-VL initialisierte MetaEmbed mit einem 7B-Modell eine Gesamt-Precision@1 von 76,6 und mit einem 32B-Modell von 78,7 erreicht und damit die aufgeführten Baselines übertrifft.
- Funktioniert MetaEmbed für das Retrieval visueller Dokumente? Ja, die Arbeit evaluiert auf ViDoRe und zeigt, dass sich die Retrieval-Qualität verbessert, je mehr Meta Embeddings verwendet werden, während MMR eine starke Leistung bei niedrigen Retrieval-Budgets bewahrt.
Wichtigste Beiträge
- Die Arbeit führt Meta Tokens als kompakte kontextualisierte Multi-Vektor-Embeddings für multimodales Retrieval über Text-, Bild- und gemischtmodale Anfragen und Kandidaten hinweg ein.
- Matryoshka Multi-Vector Retrieval trainiert grob-zu-fein verschachtelte Embedding-Gruppen und ermöglicht es einem einzigen Modell- und Indexdesign, mehrere Qualitäts-Latenz-Betriebspunkte zu unterstützen.
- MetaEmbed erzielt State-of-the-Art-Ergebnisse auf MMEB und starke Ergebnisse auf ViDoRe, während es auf Vision-Language-Modell-Backbones mit 32B Parametern skaliert.
- Die Ablationen zeigen, dass die Vorteile des Multi-Vektor-Retrievals mit der Modellgröße zunehmen und dass MMR wichtig ist, um die Retrieval-Qualität bei niedrigem Budget zu bewahren.
- Die Effizienzanalyse zeigt, dass die Bewertungslatenz für moderate Budgets gering bleibt und dass der Indexspeicher durch die Wahl ausgewogener Retrieval-Einstellungen verwaltet werden kann.
Grenzen und Vorbehalte
- Höhere Retrieval-Budgets erhöhen den Indexspeicher, doch das verschachtelte Design macht dies zu einem von Nutzenden steuerbaren Kompromiss statt zu fixen Bereitstellungskosten.
- Das größte Budget kann die Bewertungs-FLOPs erheblich erhöhen, dennoch bleibt die gemessene Latenz für viele Einstellungen praktikabel, und die Arbeit zeigt nützliche Genauigkeit bei deutlich kleineren Budgets.
- MetaEmbed erfordert weiterhin das Fine-Tuning starker VLM-Backbones, sodass künftige Arbeiten leichtere Trainingsrezepte erkunden könnten; der LoRA-Aufbau und die Experimente über mehrere Architekturen hinweg machen den Ansatz bereits breit zugänglich.
- Die Evaluation konzentriert sich auf standardmäßige Benchmarks für multimodales Retrieval und das Retrieval visueller Dokumente, sodass sehr große Produktionsindizes und spezialisierte Unternehmensdomänen als natürliche Bereitstellungsstudien offenbleiben.
- Die Methode zielt auf Retrieval statt direkt auf Generierung oder Frage-Antwort-Aufgaben ab, doch ein besseres flexibles Retrieval ist ein wertvoller Baustein für Retrieval-augmentierte multimodale Systeme.
Wie dieses Ergebnis zu lesen ist
Diese Arbeit ist am besten als ein starker Beitrag zum skalierbaren multimodalen Retrieval zu lesen: MetaEmbed bewahrt feingranulare späte Interaktion, fügt eine praktische Stellschraube für das Budget zur Testzeit hinzu und zeigt, dass größere VLMs zu effektiveren Retrieval-Modellen werden können, wenn ihnen kompakte Multi-Vektor-Schnittstellen gegeben werden.