Commonly Uncommon: Semantic Sparsity in Situation Recognition
Zusammenfassung der Pressemitteilung
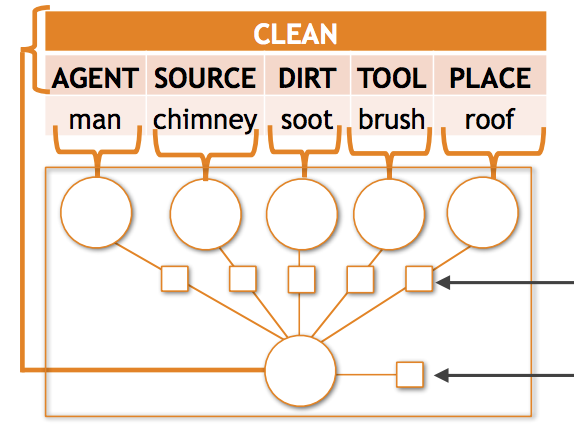
Forscher der University of Washington und des Allen Institute for Artificial Intelligence haben ein hartnäckiges Problem in der Computer Vision angepackt: Wenn KI-Systeme versuchen, das Geschehen in einem Foto in strukturierten Details zu beschreiben – indem sie nicht nur eine Aktivität wie "tragen" identifizieren, sondern auch, wer trägt, was getragen wird und wo –, neigen sie dazu, zu scheitern, sobald die Szene eine ungewöhnliche Kombination von Objekten und Rollen umfasst. Das Team stellte fest, dass im imSitu-Benchmark-Datensatz etwa 35 Prozent der erforderlichen Vorhersagen Objekt-Rollen-Paarungen umfassen, die während des Trainings weniger als zehnmal gesehen werden, und dass bestehende Modelle genau in diesen Fällen erheblich an Genauigkeit verlieren. Um dies anzugehen, entwickelten die Forscher zwei sich ergänzende Techniken. Erstens entwarfen sie ein neues mathematisches Modell namens kompositionelles Tensorpotenzial, eingebettet in ein Conditional-Random-Field-Framework, das geteilte Repräsentationen von Nomen über verschiedene Rollen hinweg lernt – sodass etwa das Wissen darüber, wie ein "Baby" aussieht, Vorhersagen unabhängig davon beeinflussen kann, ob das Baby als das Getragene oder als die tragende Person erscheint. Zweitens bauten sie eine Pipeline zur semantischen Datenanreicherung auf, die annotierte Trainingssituationen in kurze Textphrasen umwandelt, diese Phrasen nutzt, um etwa fünf Millionen Bilder aus der Google-Bildersuche abzurufen, und die verrauschten Ergebnisse durch Training mit marginaler Likelihood und iteratives Selbsttraining einbezieht. Die Kombination beider Ansätze verbesserte die Top-5-Verb-Genauigkeit um etwa 6 Prozent und die Nomen-Rollen-Genauigkeit um fast 10 Prozent gegenüber dem bisherigen Stand der Technik, mit noch größeren relativen Zugewinnen in den seltenen Fällen, auf die die Arbeit speziell abzielt. Die Ergebnisse sind von Bedeutung, weil semantische Spärlichkeit – zu viele mögliche Ausgabekombinationen, zu wenige Beispiele für die meisten von ihnen – ein weit verbreitetes Hindernis bei strukturierten Aufgaben des visuellen Verstehens ist, und diese Arbeit bietet eine konkrete, skalierbare Strategie, um KI-Systeme zuverlässiger zu machen, wenn sie auf die ungewöhnlichen Situationen treffen, die in der Praxis in der realen Welt durchaus häufig sind.
Zusammenfassung
Semantische Spärlichkeit ist eine häufige Herausforderung bei strukturierten visuellen Klassifikationsproblemen; wenn der Ausgaberaum komplex ist, wird die überwiegende Mehrheit der möglichen Vorhersagen im Trainingssatz selten, wenn überhaupt, gesehen. Diese Arbeit untersucht die semantische Spärlichkeit bei der Situationserkennung, der Aufgabe, strukturierte Zusammenfassungen dessen zu erstellen, was in Bildern geschieht, einschließlich Aktivitäten, Objekten und den Rollen, die Objekte innerhalb der Aktivität spielen. Für dieses Problem stellen wir empirisch fest, dass die meisten Objekt-Rollen-Kombinationen selten sind und dass aktuelle moderne Modelle in diesem Regime spärlicher Daten deutlich schlechter abschneiden. Wir vermeiden viele solcher Fehler, indem wir (1) eine neuartige Tensorkompositionsfunktion einführen, die lernt, Beispiele über Rollen-Nomen-Kombinationen hinweg zu teilen, und (2) unsere Trainingsdaten semantisch mit automatisch gesammelten Beispielen selten beobachteter Ausgaben anhand von Webdaten anreichern. Wenn der tensorbasierte Ansatz in ein vollständiges CRF-basiertes Modell zur strukturierten Vorhersage integriert wird, übertrifft er den bestehenden Stand der Technik mit einer relativen Verbesserung von 2,11 % bzw. 4,40 % bei der Top-5-Verb- und Nomen-Rollen-Genauigkeit. Das Hinzufügen von 5 Millionen Bildern mit unseren Techniken zur semantischen Anreicherung bringt weitere relative Verbesserungen von 6,23 % und 9,57 % bei der Top-5-Verb- und Nomen-Rollen-Genauigkeit.
Zitation
@inproceedings{yatskar2017commonly,
title = {Commonly Uncommon: Semantic Sparsity in Situation Recognition},
author = {Yatskar, Mark and Ordonez, Vicente and Zettlemoyer, Luke and Farhadi, Ali},
year = {2017},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2017},
url = {https://arxiv.org/abs/1612.00901},
}