Obj2Text: Generating Visually Descriptive Language from Object Layouts
Zusammenfassung der Pressemitteilung
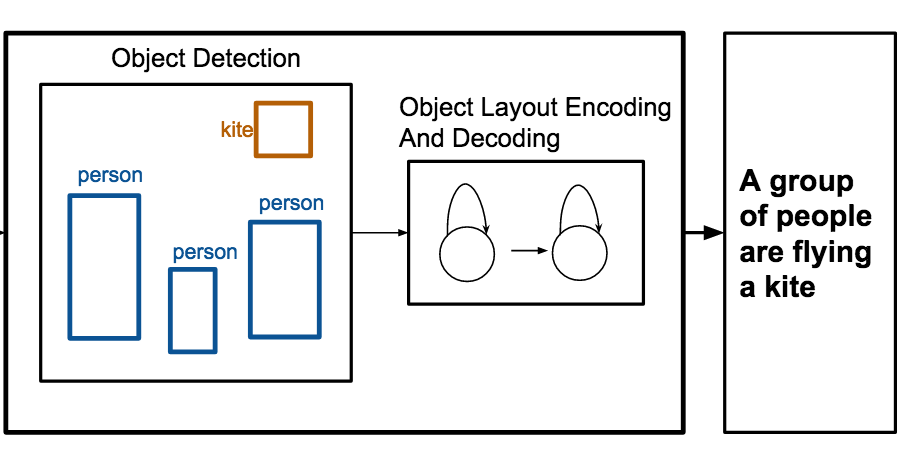
Forscher der University of Virginia haben ein System entwickelt, das automatisch Bildunterschriften schreiben kann, die eine Szene beschreiben, und dabei nicht mehr als eine Liste von Objekten und ihren Positionen in einem Bild benötigt, womit der Bedarf an rohen Pixeldaten umgangen wird. Das System namens OBJ2TEXT funktioniert, indem es Objektbezeichnungen und ihre Begrenzungsrahmenkoordinaten in ein neuronales Netz einspeist, das die Anordnung als Sequenz codiert, und diese codierte Repräsentation dann an ein zweites neuronales Netz weitergibt, das Wort für Wort einen Satz generiert. Bei Tests am standardmäßigen MS-COCO-Bilddatensatz stellte das Team fest, dass sowohl die Objektposition als auch die Objektanzahl die Qualität der Bildunterschriften bedeutsam verbesserten – das Entfernen einer der beiden verursachte messbare Leistungseinbußen – was zeigt, dass selbst eine sequenzielle Codierung räumlicher Informationen einen echten beschreibenden Wert trägt. Vielleicht praktischer noch: Als die Forscher OBJ2TEXT mit einem Objektdetektor namens YOLO und einem herkömmlichen bildbasierten Beschriftungsmodell kombinierten, übertraf das hybride System die rein bildbasierte Beschriftungs-Baseline und hob ihren CIDEr-Score auf dem MS-COCO-Benchmark von 0,863 auf 0,950; menschliche Bewerter bevorzugten die Bildunterschriften des kombinierten Systems zudem in etwa 65 Prozent der Fälle, in denen sie sich alle einig waren. Die Arbeit ist von Bedeutung, weil sie zeigt, dass strukturierte, symbolische Information über eine Szene – die Art, die von Objektdetektoren erzeugt oder im Grafikdesign und beim Storyboarding verwendet wird – pixelbasierte visuelle Merkmale bei der Sprachgenerierung ergänzen oder sogar teilweise ersetzen kann, was eine sauberere Möglichkeit bietet, zu untersuchen, was Bildbeschriftungsmodelle tatsächlich über eine Szene wissen müssen.
Zusammenfassung
Das Generieren von Bildunterschriften für Bilder ist eine Aufgabe, die in jüngster Zeit erhebliche Aufmerksamkeit erhalten hat. In dieser Arbeit konzentrieren wir uns auf die Generierung von Bildunterschriften für abstrakte Szenen, also Objektanordnungen, bei denen die einzige bereitgestellte Information eine Menge von Objekten und ihren Positionen ist. Wir schlagen OBJ2TEXT vor, ein Sequence-to-Sequence-Modell, das eine Menge von Objekten und ihren Positionen als Eingabesequenz mithilfe eines LSTM-Netzwerks codiert und diese Repräsentation mithilfe eines LSTM-Sprachmodells decodiert. Wir zeigen, dass unser Modell, obwohl es Objektanordnungen als Sequenz codiert, räumliche Beziehungen zwischen Objekten repräsentieren und Beschreibungen generieren kann, die global kohärent und semantisch relevant sind. Wir testen unseren Ansatz bei einer Aufgabe der Objektanordnungs-Beschriftung, indem wir ausschließlich Objektannotationen als Eingaben verwenden. Zusätzlich zeigen wir, dass unser Modell in Kombination mit einem modernen Objektdetektor ein Modell zur Bildbeschriftung im Test-Benchmark der standardmäßigen MS-COCO-Captioning-Aufgabe von 0,863 auf 0,950 (CIDEr-Score) verbessert.
Details
Zitation
@inproceedings{yin2017obj,
title = {Obj2Text: Generating Visually Descriptive Language from Object Layouts},
author = {Yin, Xuwang and Ordonez, Vicente},
year = {2017},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2017},
url = {https://arxiv.org/abs/1707.07102},
}