AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
Resumen de prensa
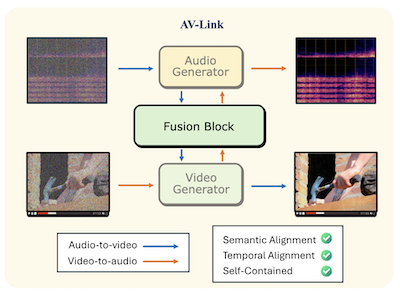
Investigadores de la Universidad Rice y Snap Inc. han desarrollado un sistema llamado AV-Link que puede generar audio sincronizado a partir de un video silencioso, o generar video que coincida con un clip de audio dado, utilizando un único marco unificado en lugar de las herramientas especializadas y separadas que han dominado este campo. El problema central que abordó el equipo es la alineación temporal: lograr que la salida generada se sincronice realmente con los eventos del material de origen, de modo que, por ejemplo, un golpe de tambor coincida exactamente con el momento en que la baqueta lo golpea, en lugar de sonar solo vagamente como un tambor. La mayoría de los enfoques existentes dependen de extractores de características preentrenados como CLIP o ImageBind para extraer el significado semántico de una modalidad y entregárselo a un generador para la otra, pero estos extractores nunca fueron diseñados pensando en una temporización precisa. En cambio, AV-Link accede directamente a las activaciones internas de modelos de difusión de audio y video preentrenados y congelados, que los investigadores descubrieron que ya contienen abundante información temporal como subproducto de aprender a generar señales que varían en el tiempo. Un módulo ligero llamado Bloque de Fusión —que añade aproximadamente 186 millones de parámetros sobre los modelos base congelados— conecta los dos generadores mediante una operación compartida de autoatención con un embedding de posición rotatorio especialmente diseñado que alinea los tokens de audio y video en el mismo marco de referencia temporal. En el benchmark estándar VGGSounds, el sistema mejoró la precisión de inicio (onset), una medida de qué tan bien se alinean los eventos sonoros con los visuales, hasta en un 76 por ciento respecto a la mejor línea base competidora y, en estudios con usuarios, fue preferido sobre el modelo MovieGen Audio de Meta, mucho más grande, para la alineación temporal el 63,6 por ciento de las veces. La importancia práctica es que un único sistema compacto podría encargarse de la generación de texto a audio, texto a video, video a audio y audio a video, lo que potencialmente simplificaría los flujos de producción para aplicaciones que van desde la posproducción cinematográfica automatizada hasta los medios generados por IA.
resumen
Proponemos AV-Link, un marco unificado para la generación de Video a Audio (V2A) y de Audio a Video (A2V) que aprovecha las activaciones de modelos de difusión de video y audio congelados para un condicionamiento intermodal alineado temporalmente. La clave de nuestro marco es un Bloque de Fusión que facilita el intercambio bidireccional de información entre los modelos de difusión de video y audio mediante operaciones de autoatención alineadas temporalmente. A diferencia de trabajos previos que emplean modelos dedicados para las tareas de A2V y V2A y dependen de extractores de características preentrenados, AV-Link logra ambas tareas en un único marco autocontenido, aprovechando directamente las características obtenidas de la modalidad complementaria (es decir, características de video para generar audio, o características de audio para generar video). Evaluaciones exhaustivas, tanto automáticas como subjetivas, demuestran que nuestro método logra una mejora sustancial en la sincronización audio-video, superando a líneas base más costosas como el modelo de video a audio de MovieGen.
detalles
cita
@inproceedings{hajiali2025av,
title = {AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Skorokhodov, Ivan and Canberk, Alper and Lee, Kwot Sin and Ordonez, Vicente and Tulyakov, Sergey},
year = {2025},
booktitle = {International Conference on Computer Vision. ICCV 2025},
url = {https://arxiv.org/abs/2412.15191},
}