Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries
Resumen de prensa
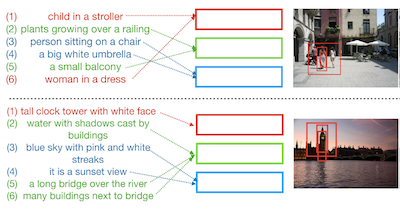
Investigadores de la Universidad de Virginia e IBM Research han desarrollado un sistema llamado Drill-down que permite a los usuarios encontrar imágenes específicas escribiendo una serie de descripciones en lenguaje natural, cada una de las cuales acota más la búsqueda en lugar de intentar capturar todo en una sola consulta. El problema que abordaban es uno familiar: las herramientas de búsqueda de imágenes existentes tienen dificultades cuando un usuario quiere localizar una fotografía muy particular de una escena compleja que contiene múltiples objetos, porque condensar la descripción de toda una escena en una sola oración es difícil e impreciso. En lugar de forzar ese enfoque de un solo intento, Drill-down permite a los usuarios comenzar de forma amplia —por ejemplo, «un grupo de personas posando en un parque»— y añadir progresivamente detalles más específicos a lo largo de varios turnos, como «hay una novia entre ellos», con el sistema actualizando sus resultados cada vez. La contribución técnica clave es un conjunto compacto de vectores de estado que almacenan y organizan el historial de las consultas de un usuario, donde cada vector aprende a rastrear una parte distinta de la escena en lugar de colapsar todo en una sola representación, que es como funcionaban los sistemas anteriores de recuperación basados en diálogo. Fundamentalmente, el equipo descubrió que podían entrenar el modelo sin recopilar costosas sesiones de búsqueda anotadas por humanos, utilizando en su lugar subtítulos de regiones de imágenes existentes del conjunto de datos Visual Genome como un sustituto económico de las consultas reales de usuarios. Las pruebas con usuarios tanto simulados como humanos reales mostraron que Drill-down superó a los métodos competidores usando en realidad menos memoria y menos parámetros, y más del 80 por ciento de los evaluadores humanos localizaron con éxito su imagen objetivo en cinco turnos. El trabajo sugiere que dividir la búsqueda de imágenes en un intercambio conversacional es un camino práctico hacia la recuperación de imágenes muy específicas en colecciones grandes y diversas.
resumen
Este artículo explora la tarea de recuperación interactiva de imágenes mediante consultas en lenguaje natural, donde un usuario proporciona progresivamente consultas de entrada para refinar un conjunto de resultados de recuperación. Además, nuestro trabajo explora este problema en el contexto de escenas de imágenes complejas que contienen múltiples objetos. Proponemos Drill-down, un marco eficaz para codificar múltiples consultas con una representación de estado compacta y eficiente que extiende significativamente los métodos actuales para la recuperación de imágenes de una sola ronda. Mostramos que el uso de múltiples rondas de consultas en lenguaje natural como entrada puede ser sorprendentemente eficaz para encontrar imágenes arbitrariamente específicas de escenas complejas. Además, encontramos que los conjuntos de datos de imágenes existentes con subtítulos textuales pueden proporcionar una forma sorprendentemente eficaz de supervisión débil para esta tarea. Comparamos nuestro método con redes existentes de codificación secuencial y de embedding, demostrando un rendimiento superior en dos benchmarks propuestos: la recuperación automática de imágenes en un escenario simulado que usa subtítulos de regiones como consultas, y la recuperación interactiva de imágenes mediante consultas reales de evaluadores humanos.
detalles
cita
@inproceedings{tan2019drill,
title = {Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries},
author = {Tan, Fuwen and Cascante-Bonilla, Paola and Guo, Xiaoxiao and Wu, Hui and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Conf. on Neural Information Processing Systems. NeurIPS 2019},
url = {https://arxiv.org/abs/1911.03826},
}