ParallelSpec: Parallel Drafter for Efficient Speculative Decoding
Resumen de prensa
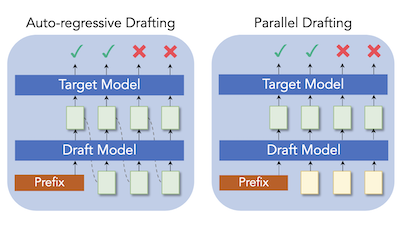
Investigadores de la Universidad Rice y Tencent AI Lab han desarrollado una nueva técnica llamada ParallelSpec que acelera un método popular para hacer más rápida la inferencia de grandes modelos de lenguaje. El desafío subyacente es que los llamados sistemas de decodificación especulativa — que utilizan un pequeño modelo de "borrador" para proponer rápidamente texto candidato que un modelo objetivo más grande luego verifica en paralelo — todavía obligan a ese pequeño redactor a generar tokens uno a la vez, creando un cuello de botella que se alarga cuanto más tokens se le pide predecir al redactor. Para solucionarlo, el equipo construyó un único modelo de borrador ligero que predice múltiples tokens futuros simultáneamente en una sola pasada hacia adelante, utilizando tokens de "máscara" de marcador de posición especialmente entrenados para incitar al modelo a mirar hacia adelante sin ejecutarse secuencialmente. También diseñaron un procedimiento de entrenamiento cuidadoso, llamado entrenamiento paralelo por grupos (group-wise parallel training), para evitar discrepancias entre cómo se entrena el modelo y cómo se ejecuta realmente en el momento de la inferencia. Cuando se integró en dos marcos de decodificación especulativa establecidos, Medusa y EAGLE, el enfoque ofreció ganancias de velocidad consistentes en una variedad de tareas de generación de texto, incluyendo traducción, resumen, razonamiento matemático y respuesta a preguntas; en Llama-2-13B alcanzó 2.84 veces la velocidad de la generación autorregresiva estándar, y elevó la aceleración de Medusa en Vicuna-7B en aproximadamente un 63 por ciento. El trabajo es importante porque aborda una ineficiencia fundamental en la etapa de redacción en lugar de simplemente ajustar cuántos tokens se proponen, lo que potencialmente hace que la aceleración sin pérdidas de LLM sea más práctica para aplicaciones en tiempo real.
resumen
La decodificación especulativa ha demostrado ser una solución eficiente para la inferencia de grandes modelos de lenguaje (LLM), donde el pequeño redactor (drafter) predice tokens futuros a bajo costo, y el modelo objetivo se aprovecha para verificarlos en paralelo. Sin embargo, la mayoría de los trabajos existentes todavía redactan tokens de forma autorregresiva para mantener la dependencia secuencial en el modelado del lenguaje, lo que consideramos una enorme carga computacional en la decodificación especulativa. Presentamos ParallelSpec, una alternativa a las estrategias de redacción autorregresivas en los enfoques de decodificación especulativa más avanzados. A diferencia de la redacción autorregresiva en la etapa especulativa, entrenamos un redactor paralelo que sirve como un modelo especulativo eficiente. ParallelSpec aprende a predecir eficientemente múltiples tokens futuros en paralelo utilizando un solo modelo, y puede integrarse en cualquier marco de decodificación especulativa que requiera alinear las distribuciones de salida del redactor y del modelo objetivo con un costo de entrenamiento mínimo. Los resultados experimentales muestran que ParallelSpec acelera los métodos de referencia en latencia hasta un 62% en pruebas de generación de texto de diferentes dominios, y logra una aceleración general de 2.84X en el modelo Llama-2-13B utilizando criterios de evaluación de terceros.
detalles
cita
@article{xiao2024parallelspec,
title = {ParallelSpec: Parallel Drafter for Efficient Speculative Decoding},
author = {Xiao, Zilin and Zhang, Hongming and Ge, Tao and Ouyang, Siru and Ordonez, Vicente and Yu, Dong},
year = {2024},
journal = {arXiv preprint arXiv:2410.05589},
url = {https://arxiv.org/abs/2410.05589},
}