Improved Visual Grounding through Self-Consistent Explanations
Résumé du communiqué de presse
Des chercheurs de Rice University et de l'UC Irvine ont mis au point une technique aidant les systèmes d'IA à localiser plus fiablement les objets dans les images à partir d'une description textuelle — une tâche connue sous le nom d'ancrage visuel. Le problème central qu'ils ont abordé est que les modèles vision-langage existants, qui apprennent à faire correspondre des images à du texte, peuvent localiser correctement un objet comme un « frisbee » mais échouer lorsque le même objet est décrit avec un mot différent, comme « disque ». Pour remédier à cela, l'équipe a créé une approche d'entraînement appelée SelfEQ (Self-consistency EQuivalence Tuning), qui utilise un grand modèle de langage pour générer automatiquement des paraphrases de légendes d'images, puis affine le modèle visuel afin que la phrase originale et sa paraphrase produisent toutes deux la même région mise en évidence dans l'image. La méthode fonctionne sans nécessiter d'annotations de boîtes englobantes, s'appuyant plutôt sur des cartes d'explication visuelle fondées sur le gradient — en l'occurrence GradCAM — comme forme de supervision faible. Testée sur trois bancs d'essai standard, SelfEQ a amélioré la précision de localisation de 4,69 points de pourcentage sur Flickr30k, de 7,68 points sur ReferIt et de 3,74 points en moyenne sur RefCOCO+, surpassant la plupart des autres méthodes qui se passent également de la supervision par boîtes englobantes et rivalisant même avec certaines qui l'utilisent. La portée pratique est un modèle qui gère un vocabulaire plus large et localise les objets de manière plus cohérente — un progrès utile pour des applications comme la recherche visuelle et l'interaction homme-machine qui dépendent de la mise en relation du langage avec des parties spécifiques d'une image.
résumé
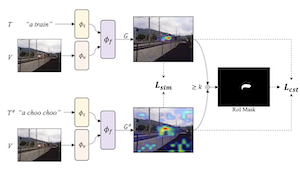
Les modèles vision-langage entraînés à faire correspondre des images à du texte peuvent être combinés à des méthodes d'explication visuelle pour pointer les emplacements d'objets spécifiques dans une image. Notre travail montre que les capacités de localisation — d'« ancrage » — de ces modèles peuvent être davantage améliorées par un affinage en faveur d'explications visuelles auto-cohérentes. Nous proposons une stratégie d'augmentation des jeux de données texte-image existants au moyen de paraphrases générées par un grand modèle de langage, ainsi que SelfEQ, une stratégie faiblement supervisée portant sur les cartes d'explication visuelle pour les paraphrases et qui encourage l'auto-cohérence. Plus précisément, pour une phrase textuelle en entrée, nous tentons de générer une paraphrase et d'affiner le modèle afin que la phrase et la paraphrase soient associées à la même région de l'image. Nous postulons que cela élargit à la fois le vocabulaire que le modèle est capable de traiter et améliore la qualité des emplacements d'objets mis en évidence par des méthodes d'explication visuelle fondées sur le gradient (par exemple GradCAM). Nous démontrons que SelfEQ améliore les performances sur Flickr30k, ReferIt et RefCOCO+ par rapport à une méthode de référence solide et à plusieurs travaux antérieurs. En particulier, comparativement à d'autres méthodes n'utilisant aucun type d'annotation de boîtes, nous obtenons 84,07% sur Flickr30k (une amélioration absolue de 4,69%), 67,40% sur ReferIt (une amélioration absolue de 7,68%), et 75,10% et 55,49% sur les ensembles de test A et B de RefCOCO+ respectivement (une amélioration absolue de 3,74% en moyenne).
détails
citation
@inproceedings{he2024improved,
title = {Improved Visual Grounding through Self-Consistent Explanations},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2024},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2024},
url = {https://arxiv.org/abs/2312.04554},
}
questions, principales contributions et limites de cet article générées automatiquement
Questions auxquelles cet article aide à répondre
- Quel problème SelfEQ aborde-t-il ? SelfEQ améliore l'ancrage visuel en amenant un modèle vision-langage à localiser des phrases équivalentes, telles que « frisbee » et « disque », dans la même région de l'image.
- Comment la méthode fonctionne-t-elle sans supervision par boîtes englobantes ? Elle utilise les cartes d'explication GradCAM d'un modèle vision-langage existant comme supervision faible, puis entraîne le modèle afin qu'une phrase originale et sa paraphrase produisent des cartes de localisation cohérentes.
- Pourquoi les paraphrases générées par LLM sont-elles utiles ici ? Les paraphrases élargissent les formulations que le modèle peut traiter et créent des paires d'équivalence qui apprennent au modèle à ancrer de manière cohérente des descriptions sémantiquement similaires.
- Quel est le rôle de l'objectif SelfEQ ? L'objectif combine la similarité des cartes de chaleur avec un terme de cohérence de la région d'intérêt afin que les invites paraphrasées s'alignent spatialement tout en évitant des cartes d'explication uniformes triviales.
- Quels bancs d'essai montrent l'impact de la méthode ? L'article rapporte des améliorations sur Flickr30k, ReferIt et RefCOCO+, avec notamment de solides résultats parmi les méthodes n'utilisant pas d'annotations de boîtes.
Principales contributions
- L'article introduit le Self-consistency EQuivalence Tuning, un objectif faiblement supervisé pour améliorer l'ancrage visuel grâce à des explications cohérentes entre textes paraphrasés.
- Il montre que les paraphrases générées par LLM peuvent servir de signaux d'entraînement extensibles pour l'ancrage visuel, transformant l'équivalence linguistique en supervision spatiale utile.
- La méthode améliore un pipeline d'ancrage fondé sur ALBEF sans nécessiter de boîtes englobantes, de masques de segmentation, de détecteurs d'objets ou de réseaux de proposition de boîtes.
- SelfEQ obtient des gains substantiels par rapport à de solides références faiblement supervisées, dont 84,07% sur Flickr30k, 67,40% sur ReferIt, ainsi qu'une précision améliorée au jeu de pointage sur RefCOCO+.
- Les études d'ablation clarifient pourquoi l'affinage explicite d'équivalence est important : ajouter simplement des paraphrases comme paires image-texte supplémentaires est moins efficace que d'imposer directement des explications visuelles auto-cohérentes.
Limites et mises en garde
- SelfEQ est conçu pour l'ancrage faiblement supervisé avec des cartes d'explication, de sorte qu'il complète plutôt qu'il ne remplace les systèmes d'ancrage entièrement supervisés lorsque des boîtes de haute qualité sont disponibles.
- La méthode dépend de la qualité des paraphrases générées, mais l'article utilise une stratégie claire d'invite et de filtrage et montre que les paires d'équivalence résultantes apportent des gains pratiques.
- Comme elle s'appuie sur des explications de type GradCAM issues d'un modèle vision-langage de base, les performances peuvent refléter les forces du modèle sous-jacent ; cela rend SelfEQ particulièrement précieux comme stratégie d'affinage pour améliorer des modèles existants.
- L'évaluation est centrée sur des bancs d'essai d'ancrage standard et la précision au jeu de pointage, laissant des contextes plus larges du monde réel — recherche visuelle, robotique et accessibilité — comme prochaines applications naturelles.
- L'approche se concentre sur l'ancrage de phrases et de régions plutôt que sur un raisonnement visuel ouvert complet, ce qui maintient la contribution bien ciblée et facilite l'interprétation des gains rapportés.
Comment interpréter ce résultat
Cet article se lit au mieux comme une contribution solide à l'ancrage visuel faiblement supervisé : SelfEQ transforme la cohérence des paraphrases en un signal d'entraînement pratique, améliorant la précision de localisation et la robustesse du vocabulaire sans nécessiter d'annotations coûteuses d'emplacement d'objets.