AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
Sintesi del comunicato stampa
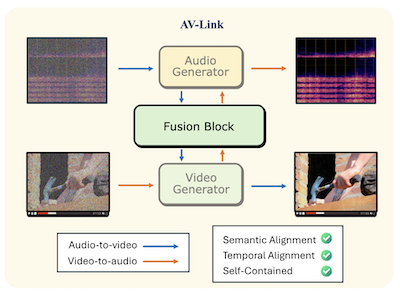
I ricercatori della Rice University e di Snap Inc. hanno sviluppato un sistema chiamato AV-Link in grado di generare audio sincronizzato a partire da video muto, o di generare video per abbinarsi a una data clip audio, utilizzando un unico framework unificato anziché gli strumenti specializzati separati che hanno dominato questo campo. Il problema centrale affrontato dal team è l'allineamento temporale — fare in modo che l'output generato si sincronizzi effettivamente con gli eventi nel materiale di partenza, così che, ad esempio, il colpo di tamburo cada esattamente quando la bacchetta colpisce, anziché suonare semplicemente in modo vagamente simile a un tamburo. La maggior parte degli approcci esistenti si affida a estrattori di caratteristiche preaddestrati come CLIP o ImageBind per estrarre il significato semantico da una modalità e fornirlo a un generatore per l'altra, ma questi estrattori non sono mai stati progettati pensando a una temporizzazione precisa. AV-Link, invece, attinge direttamente alle attivazioni interne di modelli di diffusione audio e video congelati e preaddestrati, che i ricercatori hanno scoperto contenere già ricche informazioni temporali come sottoprodotto dell'apprendimento a generare segnali variabili nel tempo. Un modulo leggero chiamato Fusion Block — che aggiunge circa 186 milioni di parametri sopra i modelli di base congelati — connette i due generatori attraverso un'operazione di self-attention condivisa con un rotary position embedding appositamente progettato che allinea i token audio e video allo stesso sistema di riferimento temporale. Sul benchmark standard VGGSounds, il sistema ha migliorato l'accuratezza dell'onset, una misura di quanto bene gli eventi sonori si allineino con gli eventi visivi, fino al 76 percento rispetto al miglior baseline concorrente, e negli studi con utenti è stato preferito al modello MovieGen Audio di Meta, molto più grande, per l'allineamento temporale nel 63,6 percento dei casi. Il significato pratico è che un unico sistema compatto potrebbe gestire la generazione text-to-audio, text-to-video, video-to-audio e audio-to-video, semplificando potenzialmente le pipeline di produzione per applicazioni che vanno dalla post-produzione cinematografica automatizzata ai media generati dall'IA.
abstract
Proponiamo AV-Link, un framework unificato per la generazione Video-to-Audio (A2V) e Audio-to-Video (A2V) che sfrutta le attivazioni di modelli di diffusione video e audio congelati per un condizionamento cross-modale temporalmente allineato. L'elemento chiave del nostro framework è un Fusion Block che facilita lo scambio bidirezionale di informazioni tra i modelli di diffusione video e audio attraverso operazioni di self-attention temporalmente allineate. A differenza dei lavori precedenti che utilizzano modelli dedicati per i compiti A2V e V2A e si affidano a estrattori di caratteristiche preaddestrati, AV-Link realizza entrambi i compiti in un unico framework autonomo, sfruttando direttamente le caratteristiche ottenute dalla modalità complementare (cioè caratteristiche video per generare audio, o caratteristiche audio per generare video). Estese valutazioni automatiche e soggettive dimostrano che il nostro metodo ottiene un miglioramento sostanziale nella sincronizzazione audio-video, superando baseline più costosi come il modello video-to-audio MovieGen.
dettagli
citazione
@inproceedings{hajiali2025av,
title = {AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Skorokhodov, Ivan and Canberk, Alper and Lee, Kwot Sin and Ordonez, Vicente and Tulyakov, Sergey},
year = {2025},
booktitle = {International Conference on Computer Vision. ICCV 2025},
url = {https://arxiv.org/abs/2412.15191},
}