Estimating and Maximizing Mutual Information for Knowledge Distillation
Sintesi del comunicato stampa
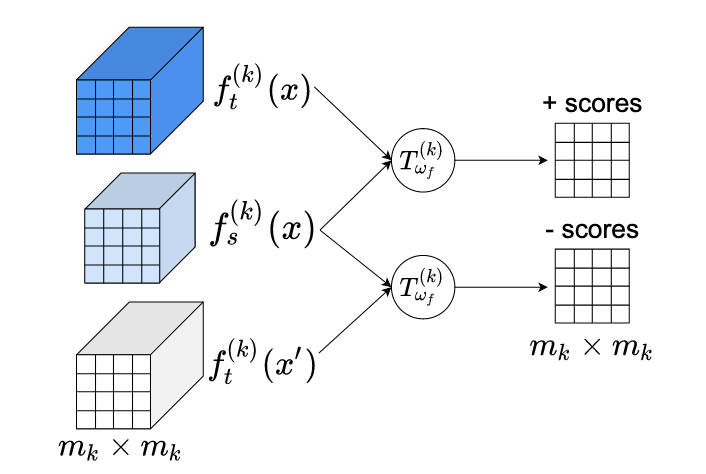
I ricercatori della University of Virginia e della Rice University hanno sviluppato una nuova tecnica per rimpicciolire grandi modelli di intelligenza artificiale fino a dimensioni eseguibili su telefoni e altri dispositivi con risorse limitate, senza sacrificarne troppo l'accuratezza. La sfida centrale in questo campo, noto come knowledge distillation, consiste nel far sì che una rete neurale "student" più piccola assorba informazioni utili da una rete "teacher" più grande e più capace. I metodi esistenti tipicamente lo fanno facendo corrispondere gli output o le rappresentazioni intermedie delle due reti utilizzando semplici metriche di distanza, che possono incontrare difficoltà quando il teacher e lo student hanno architetture interne molto diverse. Il nuovo framework, chiamato MIMKD (Mutual Information Maximization Knowledge Distillation), adotta un approccio diverso utilizzando un obiettivo di contrastive learning radicato nella teoria dell'informazione — nello specifico, uno stimatore basato sulla divergenza di Jensen-Shannon — per stimare e massimizzare simultaneamente l'informazione mutua condivisa tra le rappresentazioni delle due reti, sia a livello di feature globali finali sia a livelli di feature locali e intermedi a grana più fine. Un vantaggio pratico è che questa formulazione, a differenza di metodi concorrenti come la Contrastive Representation Distillation, richiede un solo negative sample durante l'addestramento anziché migliaia, rendendola molto meno onerosa in termini di memoria e più applicabile ai livelli intermedi della rete. Nei test sui benchmark di classificazione di immagini CIFAR-100 e ImageNet, MIMKD ha superato costantemente le alternative consolidate su un'ampia gamma di abbinamenti teacher-student, inclusi i casi in cui le due reti avevano progettazioni molto diverse, aumentando l'accuratezza di una ShuffleNetV2 di quasi 5 punti percentuali utilizzando un teacher ResNet-50 e migliorando una ResNet-18 su ImageNet di 1.44 punti percentuali rispetto alla sua baseline — risultati che suggeriscono che l'approccio potrebbe contribuire a rendere più pratico il deployment di modelli di IA capaci ai margini della rete (edge).
abstract
In questo lavoro, proponiamo la Mutual Information Maximization Knowledge Distillation (MIMKD). Il nostro metodo utilizza un obiettivo contrastive per stimare e massimizzare simultaneamente un limite inferiore sull'informazione mutua delle rappresentazioni di feature locali e globali tra una rete teacher e una rete student. Dimostriamo attraverso esperimenti approfonditi che ciò può essere utilizzato per migliorare le prestazioni di modelli a bassa capacità trasferendo conoscenza da modelli più performanti ma computazionalmente costosi. Questo può essere usato per produrre modelli migliori eseguibili su dispositivi con scarse risorse computazionali. Il nostro metodo è flessibile: possiamo distillare conoscenza da teacher con architetture di rete arbitrarie verso reti student arbitrarie. I nostri risultati empirici mostrano che MIMKD supera gli approcci concorrenti su un'ampia gamma di coppie student-teacher con capacità diverse, con architetture diverse e quando le reti student hanno una capacità estremamente bassa. Siamo in grado di ottenere un'accuratezza del 74.55% su CIFAR100 con una ShufflenetV2, a partire da un'accuratezza di base del 69.8%, distillando conoscenza da ResNet-50. Su Imagenet miglioriamo una rete ResNet-18 dal 68.88% al 70.32% di accuratezza (1.44%+) utilizzando una rete teacher ResNet-34.
citazione
@inproceedings{shrivastava2023estimating,
title = {Estimating and Maximizing Mutual Information for Knowledge Distillation},
author = {Shrivastava, Aman and Qi, Yanjun and Ordonez, Vicente},
year = {2023},
booktitle = {Workshop on Fair, Data Efficient and Trusted Computer Vision at CVPR 2023},
url = {https://arxiv.org/abs/2110.15946},
}