Text2Scene: Generating Compositional Scenes from Textual Descriptions
Sintesi del comunicato stampa
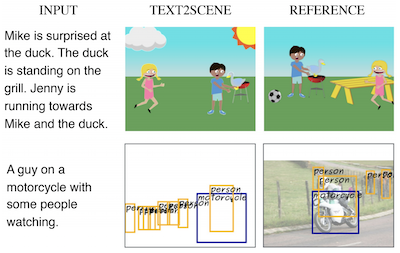
I ricercatori della University of Virginia e del Thomas J. Watson Research Center di IBM hanno sviluppato un sistema chiamato Text2Scene in grado di generare automaticamente scene visive a partire da descrizioni scritte — senza affidarsi alle Generative Adversarial Networks, o GAN, da cui dipende la maggior parte degli approcci concorrenti. Anziché cercare di sintetizzare un'intera immagine in una sola volta, il sistema funziona più come un illustratore attento, leggendo una frase e poi posizionando gli oggetti uno alla volta su una tela bianca, decidendo a ogni passo cosa aggiungere dopo, dove collocarlo e che aspetto debba avere. Il modello utilizza meccanismi di attenzione per concentrarsi su diverse parti del testo in input mentre costruisce la scena, così quando una descrizione dice "Jenny is running towards Mike", il sistema riesce a capire che l'orientamento di Jenny dipende da dove si trova già Mike. Il team ha testato il proprio approccio su tre compiti piuttosto diversi — generare scene di clip-art a fumetti, prevedere mappe realistiche di disposizione degli oggetti e assemblare fotografie composite a partire da frammenti di immagini recuperati — utilizzando lo stesso framework di base con sole lievi modifiche per ciascuno. Nei confronti diretti, Text2Scene ha eguagliato o battuto i rivali basati su GAN sulla maggior parte delle metriche automatiche di qualità e li ha superati tutti, incluso il robusto modello AttnGAN, quando valutatori umani hanno giudicato quali immagini corrispondessero meglio alle loro didascalie. Il lavoro è degno di nota sia perché aggira il processo di addestramento delle GAN, notoriamente capriccioso, sia perché produce output interpretabili, passo dopo passo, che rendono più facile capire perché il modello abbia compiuto le scelte che ha compiuto — una qualità di cui i sistemi di generazione puramente basati sui pixel generalmente difettano.
abstract
In questo articolo proponiamo Text2Scene, un modello che genera varie forme di rappresentazioni composizionali di scene a partire da descrizioni in linguaggio naturale. A differenza dei lavori recenti, il nostro metodo NON utilizza le Generative Adversarial Networks (GAN). Text2Scene impara invece a generare in sequenza gli oggetti e i loro attributi (posizione, dimensione, aspetto, ecc.) a ogni passo temporale prestando attenzione a diverse parti del testo in input e allo stato attuale della scena generata. Mostriamo che, con lievi modifiche, il framework proposto è in grado di gestire la generazione di diverse forme di rappresentazioni di scene, incluse scene in stile cartone animato, disposizioni di oggetti corrispondenti a immagini reali e immagini sintetiche. Il nostro metodo non solo è competitivo rispetto ai metodi allo stato dell'arte basati su GAN secondo le metriche automatiche e superiore secondo i giudizi umani, ma ha anche il vantaggio di produrre risultati interpretabili.
dettagli
citazione
@inproceedings{tan2019text,
title = {Text2Scene: Generating Compositional Scenes from Textual Descriptions},
author = {Tan, Fuwen and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2019},
url = {https://arxiv.org/abs/1809.01110},
}