AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
プレスリリース要約
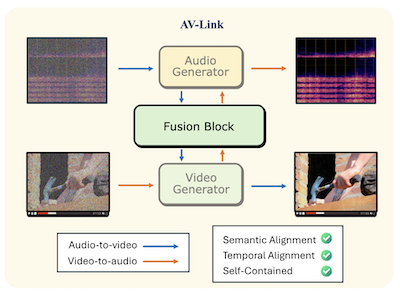
Rice大学とSnap Inc.の研究者らは、この分野を支配してきた別個の専用ツールではなく、単一の統一フレームワークを使用して、無音の動画から同期したオーディオを生成したり、与えられたオーディオクリップに合わせて動画を生成したりできる、AV-Linkと呼ばれるシステムを開発しました。チームが取り組んだ中核的な問題は時間的整合性です。すなわち、生成された出力をソース素材内のイベントと実際に同期させ、例えば、単に漠然とドラムのように聞こえるのではなく、ドラムスティックが当たったまさにその瞬間にドラムビートが鳴るようにすることです。既存のほとんどのアプローチは、CLIPやImageBindのような事前学習済みの特徴抽出器に依存して、あるモダリティから意味を引き出し、それをもう一方のための生成器に供給しますが、これらの抽出器は厳密なタイミングを念頭に置いて設計されたものではありませんでした。代わりに、AV-Linkは凍結された事前学習済みのオーディオ拡散モデルと動画拡散モデルの内部活性化に直接アクセスします。研究者らは、これらが時変信号を生成することを学習した副産物として、すでに豊富な時間的情報を含んでいることを発見しました。Fusion Blockと呼ばれる軽量モジュール(凍結されたベースモデルの上に約1億8,600万のパラメータを追加)は、オーディオトークンと動画トークンを同じ時間的基準フレームに整合させる特別に設計された回転位置埋め込みを伴う共有セルフアテンション操作を通じて、2つの生成器を接続します。標準のVGGSoundsベンチマークにおいて、本システムは、音声イベントが視覚的イベントとどれだけよく一致するかの尺度であるオンセット精度を、最良の競合ベースラインに対して最大76%向上させ、ユーザー調査では時間的整合性についてMetaのはるかに大規模なMovieGen Audioモデルよりも63.6%の確率で好まれました。実用的な意義は、単一のコンパクトなシステムがテキストからオーディオ、テキストから動画、動画からオーディオ、オーディオから動画への生成を扱えることであり、これは自動化された映画のポストプロダクションからAI生成メディアに至るまでのアプリケーションの制作パイプラインを簡素化する可能性があります。
要旨
私たちはAV-Linkを提案します。これは、時間的に整合したクロスモーダルな条件付けのために、凍結された動画拡散モデルとオーディオ拡散モデルの活性化を活用する、動画からオーディオへの生成(A2V)およびオーディオから動画への生成(A2V)のための統一フレームワークです。本フレームワークの鍵は、時間的に整合したセルフアテンション操作を通じて動画拡散モデルとオーディオ拡散モデルの間の双方向の情報交換を促進するFusion Blockです。A2VとV2Aのタスクに専用のモデルを使用し事前学習済みの特徴抽出器に依存する従来研究とは異なり、AV-Linkは補完的なモダリティによって得られた特徴量(すなわち、オーディオを生成するための動画特徴量、または動画を生成するためのオーディオ特徴量)を直接活用することで、単一の自己完結型フレームワークで両方のタスクを達成します。広範な自動評価および主観評価は、本手法がオーディオと動画の同期において大幅な改善を達成し、MovieGenの動画からオーディオへのモデルといったより高コストなベースラインを上回ることを実証しています。
詳細
引用
@inproceedings{hajiali2025av,
title = {AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Skorokhodov, Ivan and Canberk, Alper and Lee, Kwot Sin and Ordonez, Vicente and Tulyakov, Sergey},
year = {2025},
booktitle = {International Conference on Computer Vision. ICCV 2025},
url = {https://arxiv.org/abs/2412.15191},
}