Improved Visual Grounding through Self-Consistent Explanations
プレスリリース要約
ライス大学とカリフォルニア大学アーバイン校の研究者らは、テキストによる説明を与えられたときに、AIシステムが画像内の物体の位置をより信頼性高く特定するのを助ける技術を開発しました。これは視覚的グラウンディングとして知られるタスクです。彼らが取り組んだ中心的な問題は、画像とテキストを対応づけることを学習する既存の視覚言語モデルが、「フリスビー(frisbee)」のような物体を正しく位置特定できる一方で、同じ物体が「ディスク(disc)」のような別の語で説明されると失敗してしまうことです。これを解決するため、研究チームはSelfEQ(Self-consistency EQuivalence Tuning、自己整合性等価チューニング)と呼ばれる訓練アプローチを開発しました。これは、大規模言語モデルを用いて画像キャプションの言い換えを自動生成し、その後、元の句とその言い換えの両方が画像内の同じ強調領域を生成するように視覚モデルをファインチューニングするものです。この手法は、いかなるバウンディングボックスアノテーションも必要とせずに機能し、代わりに勾配ベースの視覚的説明マップ、具体的にはGradCAMを弱教師の一形態として利用します。3つの標準的なベンチマークでテストした結果、SelfEQは位置特定精度をFlickr30kで4.69パーセントポイント、ReferItで7.68ポイント、RefCOCO+で平均3.74ポイント改善し、同様にバウンディングボックスの教師を用いない他のほとんどの手法を上回り、それを用いる一部の手法にさえ匹敵しました。実用上の成果は、より広い語彙を扱い、物体をより一貫して位置特定するモデルであり、これは言語を画像の特定の部分に結びつけることに依存する視覚検索や人間と機械の対話といった応用にとって有用な進歩です。
要旨
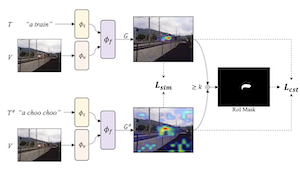
画像とテキストを対応づけるよう訓練された視覚言語モデルは、視覚的説明手法と組み合わせることで、画像内の特定の物体の位置を指し示すことができます。私たちの研究は、これらのモデルの位置特定能力、すなわち「グラウンディング」能力が、自己整合的な視覚的説明のためにファインチューニングすることでさらに改善できることを示します。私たちは、大規模言語モデルを用いて既存のテキスト・画像データセットを言い換え(パラフレーズ)で拡張する戦略と、言い換えに対する視覚的説明マップ上で自己整合性を促す弱教師あり戦略であるSelfEQを提案します。具体的には、入力されたテキスト句に対して言い換えを生成し、その句と言い換えが画像内の同じ領域に対応づけられるようモデルをファインチューニングします。私たちは、これがモデルが扱える語彙を拡張するとともに、勾配ベースの視覚的説明手法(たとえばGradCAM)によって強調される物体位置の品質を改善すると主張します。私たちは、SelfEQがFlickr30k、ReferIt、RefCOCO+において、強力なベースライン手法やいくつかの先行研究を上回る性能を達成することを実証します。特に、いかなる種類のボックスアノテーションも使用しない他の手法と比較して、Flickr30kで84.07%(絶対値で4.69%の改善)、ReferItで67.40%(絶対値で7.68%の改善)、RefCOCO+のテストセットAおよびBでそれぞれ75.10%、55.49%(平均で絶対値3.74%の改善)を獲得します。
詳細
引用
@inproceedings{he2024improved,
title = {Improved Visual Grounding through Self-Consistent Explanations},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2024},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2024},
url = {https://arxiv.org/abs/2312.04554},
}
この論文について自動生成された質問、主な貢献、および限界
この論文が答える助けとなる質問
- SelfEQはどのような問題に対処しますか。SelfEQは、視覚言語モデルが「frisbee」と「disc」のような等価な句を画像内の同じ領域に位置特定するようにすることで、視覚的グラウンディングを改善します。
- この手法はバウンディングボックスの教師なしでどのように機能しますか。既存の視覚言語モデルから得たGradCAMの説明マップを弱教師として用い、元の句とその言い換えが一貫した位置特定マップを生成するようにモデルを訓練します。
- ここでLLMが生成した言い換えはなぜ有用なのですか。言い換えはモデルが扱える表現を拡張し、意味的に類似した記述を一貫してグラウンディングするようモデルに教える等価ペアを作り出します。
- SelfEQの目的関数の役割は何ですか。この目的関数はヒートマップの類似性と関心領域の一貫性の項を組み合わせ、言い換えられたプロンプトが空間的に整合しつつ、自明な一様の説明マップを避けるようにします。
- どのベンチマークがこの手法の効果を示していますか。この論文はFlickr30k、ReferIt、RefCOCO+での改善を報告しており、ボックスアノテーションを使用しない手法の中で強力な結果を含んでいます。
主な貢献
- この論文は、言い換えられたテキストにわたる一貫した説明を通じて視覚的グラウンディングを改善する弱教師あり目的関数である、自己整合性等価チューニング(Self-consistency EQuivalence Tuning)を導入しています。
- LLMが生成した言い換えが視覚的グラウンディングのためのスケーラブルな訓練信号として利用でき、言語的等価性を有用な空間的教師に変えられることを示しています。
- この手法は、バウンディングボックス、セグメンテーションマスク、物体検出器、ボックス提案ネットワークを必要とせずに、ALBEFベースのグラウンディングパイプラインを改善します。
- SelfEQは、Flickr30kで84.07%、ReferItで67.40%、そしてRefCOCO+のポインティングゲーム精度の改善を含め、強力な弱教師ありベースラインに対して大幅な向上を達成します。
- アブレーションは、明示的な等価チューニングがなぜ重要なのかを明らかにしています。すなわち、単に言い換えを追加の画像テキストペアとして加えることは、自己整合的な視覚的説明を直接強制することよりも効果が低いのです。
限界と注意点
- SelfEQは説明マップを用いた弱教師ありグラウンディングのために設計されているため、高品質なボックスが利用可能な場合には、完全教師ありのグラウンディングシステムを置き換えるのではなく補完します。
- この手法は生成される言い換えの品質に依存しますが、この論文は明確なプロンプティングとフィルタリングの戦略を用いており、結果として得られる等価ペアが実用的な向上をもたらすことを示しています。
- ベースとなる視覚言語モデルのGradCAMスタイルの説明を土台にしているため、性能は基盤モデルの強みを反映しうるものです。これによりSelfEQは、既存モデルを改善するためのチューニング戦略として特に価値あるものになります。
- 評価は標準的なグラウンディングベンチマークとポインティングゲーム精度を中心としており、より広範な実世界の視覚検索、ロボティクス、アクセシビリティの設定を自然な次の応用先として残しています。
- このアプローチは完全にオープンエンドな視覚推論ではなく、句と領域のグラウンディングに焦点を当てており、これにより貢献が的を絞ったものとなり、報告された向上を解釈しやすくしています。
この結果の読み解き方
この論文は、弱教師あり視覚的グラウンディングへの力強い貢献として読むのが最適です。SelfEQは言い換えの一貫性を実用的な訓練信号に変え、高価な物体位置アノテーションを必要とせずに位置特定精度と語彙の頑健性を改善します。