プレスリリース要約
バージニア大学とライス大学の研究者らは、大規模な人工知能モデルを、その精度を大きく犠牲にすることなく、スマートフォンやその他の資源が限られたデバイスで実行できるサイズに縮小する新しい技術を開発しました。知識蒸留として知られるこの分野の中心的な課題は、より小さな「生徒」ニューラルネットワークに、より大きく高性能な「教師」ネットワークから有用な情報を吸収させることです。既存の手法は通常、単純な距離尺度を用いて2つのネットワークの出力や中間表現を一致させることでこれを行いますが、教師と生徒の内部アーキテクチャが大きく異なる場合に苦戦することがあります。MIMKD(Mutual Information Maximization Knowledge Distillation、相互情報量最大化知識蒸留)と呼ばれる新しいフレームワークは、情報理論に根ざした対照学習の目的、具体的にはJensen-Shannonダイバージェンスに基づく推定器を用いて、2つのネットワークの表現の間で共有される相互情報量を、最終的な大域特徴のレベルでも、より細粒度の局所的・中間的な特徴のレベルでも、同時に推定し最大化するという異なるアプローチをとります。実用的な利点は、この定式化が、Contrastive Representation Distillationのような競合手法とは異なり、訓練中に数千個ではなく単一の負例しか必要としないことであり、これによりメモリ消費がはるかに少なくなり、中間ネットワーク層への適用がより容易になります。CIFAR-100およびImageNet画像分類ベンチマークでのテストでは、MIMKDは、2つのネットワークが非常に異なる設計を持つ場合を含め、幅広い教師・生徒の組み合わせにわたって確立された代替手法を一貫して上回り、ResNet-50の教師を用いてShuffleNetV2の精度を約5パーセントポイント引き上げ、ImageNetでのResNet-18をそのベースラインより1.44パーセントポイント改善しました。これらの結果は、このアプローチが、高性能なAIモデルをエッジで展開することをより実用的にするのに役立ちうることを示唆しています。
要旨
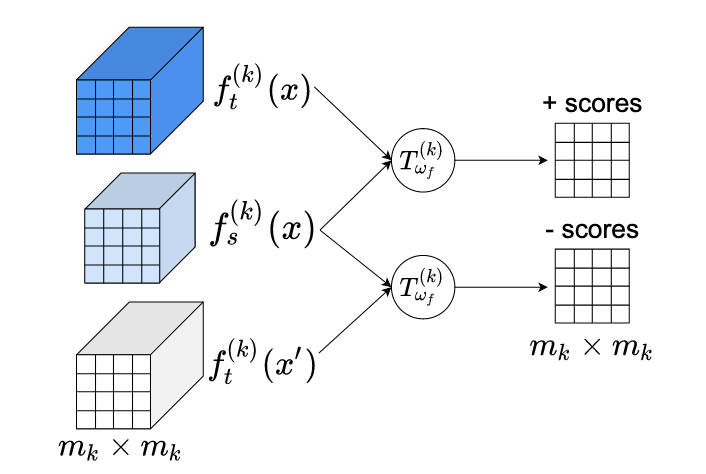
本研究では、私たちは相互情報量最大化知識蒸留(Mutual Information Maximization Knowledge Distillation、MIMKD)を提案します。私たちの手法は、対照目的を用いて、教師ネットワークと生徒ネットワークの間の局所的および大域的な特徴表現の相互情報量の下界を、同時に推定し最大化します。私たちは広範な実験を通じて、これが、より高性能だが計算コストの高いモデルから知識を転移することで、低容量モデルの性能を改善するために使用できることを実証します。これは、計算資源の少ないデバイスで実行できるより優れたモデルを生み出すために使用できます。私たちの手法は柔軟であり、任意のネットワークアーキテクチャを持つ教師から任意の生徒ネットワークへ知識を蒸留できます。私たちの実証結果は、MIMKDが、異なる容量、異なるアーキテクチャを持つ幅広い生徒・教師ペアにわたって、また生徒ネットワークが極めて低容量の場合に、競合する手法を上回ることを示しています。私たちは、ResNet-50から知識を蒸留することで、69.8%というベースライン精度から、ShufflenetV2を用いてCIFAR100で74.55%の精度を獲得できます。ImageNetでは、ResNet-34の教師ネットワークを用いて、ResNet-18ネットワークを68.88%から70.32%の精度へと(+1.44%)改善します。
引用
@inproceedings{shrivastava2023estimating,
title = {Estimating and Maximizing Mutual Information for Knowledge Distillation},
author = {Shrivastava, Aman and Qi, Yanjun and Ordonez, Vicente},
year = {2023},
booktitle = {Workshop on Fair, Data Efficient and Trusted Computer Vision at CVPR 2023},
url = {https://arxiv.org/abs/2110.15946},
}