プレスリリース要約
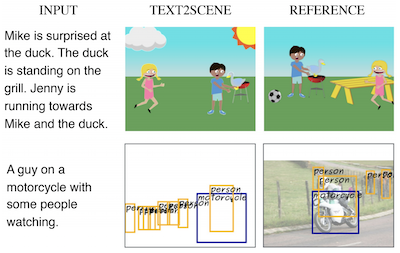
バージニア大学とIBMのThomas J. Watson Research Centerの研究者らは、ほとんどの競合アプローチが依存している敵対的生成ネットワーク(GAN)に頼ることなく、文章による記述から視覚的なシーンを自動的に生成できる、Text2Sceneと呼ばれるシステムを開発した。画像全体を一度に合成しようとするのではなく、このシステムは慎重なイラストレーターのように機能し、文を読んでから物体を一つずつ白紙のキャンバスに配置していき、各ステップで次に何を追加するか、どこに置くか、それがどのように見えるべきかを決定する。モデルはシーンを構築する際に入力テキストの異なる部分に注目するために注意機構を用いるため、記述が「JennyがMikeに向かって走っている」という場合、システムはJennyの向きがMikeがすでに立っている場所に依存することを把握できる。チームは、漫画のクリップアートのシーンの生成、現実的な物体レイアウトマップの予測、検索された画像パッチからの合成写真の組み立てという、かなり異なる3つのタスクにわたって、それぞれにわずかな修正を加えるだけで同じ基盤フレームワークを用いてアプローチをテストした。直接の比較において、Text2Sceneはほとんどの自動品質指標でGANベースの競合手法に匹敵するか上回り、人間の評価者がどの画像がキャプションによりよく一致するかを判断した際には、強力なAttnGANモデルを含むそれらすべてを上回った。この研究が注目に値するのは、難しいことで知られるGANの訓練プロセスを回避している点と、モデルがなぜそのような選択をしたのかを理解しやすくする、解釈可能で段階的な出力を生成する点の両方による。これは純粋に画素ベースの生成システムが一般に欠いている性質である。
要旨
本論文では、自然言語による記述からさまざまな形態の構成的シーン表現を生成するモデルであるText2Sceneを提案する。最近の研究とは異なり、本手法は敵対的生成ネットワーク(GAN)を使用しない。Text2Sceneは代わりに、入力テキストの異なる部分と生成されたシーンの現在の状態に注意を向けることで、各時間ステップにおいて物体とその属性(位置、サイズ、外観など)を逐次的に生成することを学習する。我々は、わずかな修正のもとで、提案フレームワークが漫画のようなシーン、実画像に対応する物体レイアウト、合成画像を含むさまざまな形態のシーン表現の生成を扱えることを示す。本手法は、自動評価指標を用いた場合に最先端のGANベースの手法と比較して競合的であるだけでなく、人間の判断に基づけば優れており、さらに解釈可能な結果を生成できるという利点も持つ。
詳細
引用
@inproceedings{tan2019text,
title = {Text2Scene: Generating Compositional Scenes from Textual Descriptions},
author = {Tan, Fuwen and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2019},
url = {https://arxiv.org/abs/1809.01110},
}