プレスリリース要約
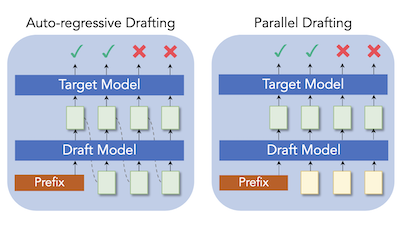
ライス大学とTencent AI Labの研究者らは、大規模言語モデルの推論を高速化するための普及した手法をさらに速くするParallelSpecと呼ばれる新しい技術を開発した。根底にある課題は、いわゆる投機的デコーディングシステム、すなわち小さな「ドラフト」モデルを用いて候補テキストを素早く提案し、より大きなターゲットモデルがそれを並列に確認するシステムが、依然としてその小さなドラフターに一度に一つずつトークンを生成させ、ドラフターに予測を求めるトークンが多いほど長くなるボトルネックを生み出していることである。これを修正するため、研究チームは、一回の順伝播で複数の将来のトークンを同時に予測する単一の軽量なドラフトモデルを構築し、特別に訓練されたプレースホルダーの「マスク」トークンを用いてモデルを逐次実行することなく先読みするよう促した。彼らはまた、モデルの訓練方法と推論時の実際の実行方法との間の不一致を防ぐため、グループ単位の並列訓練と呼ばれる慎重な訓練手順を設計した。確立された二つの投機的デコーディングフレームワークであるMedusaとEAGLEに組み込んだところ、このアプローチは翻訳、要約、数学的推論、質問応答を含む様々なテキスト生成タスクにわたって一貫した速度向上をもたらした。Llama-2-13Bでは標準的な自己回帰生成の2.84倍の速度に達し、Vicuna-7BでのMedusaの高速化をおよそ63パーセント引き上げた。本研究が重要なのは、提案されるトークン数を単に調整するのではなく、ドラフト段階の根本的な非効率に対処しており、ロスのないLLMの高速化をリアルタイムアプリケーションにとってより実用的なものにし得るからである。
要旨
投機的デコーディングは、大規模言語モデル(LLM)の推論に対する効率的な解決策であることが証明されており、そこでは小さなドラフターが低コストで将来のトークンを予測し、ターゲットモデルがそれらを並列に検証するために活用される。しかし、既存の研究の大半は、言語モデリングにおける逐次的依存関係を維持するため、依然として自己回帰的にトークンをドラフトしており、我々はこれを投機的デコーディングにおける大きな計算負担とみなしている。我々は、最先端の投機的デコーディング手法における自己回帰的なドラフト戦略の代替であるParallelSpecを提示する。投機段階における自己回帰的なドラフトとは対照的に、我々は効率的な投機モデルとして機能する並列ドラフターを訓練する。ParallelSpecは、単一のモデルを用いて複数の将来のトークンを並列に効率よく予測することを学習し、最小限の訓練コストでドラフターとターゲットモデルの出力分布を整合させる必要のある任意の投機的デコーディングフレームワークに統合できる。実験結果は、ParallelSpecが異なる分野のテキスト生成ベンチマークにおいてベースライン手法の遅延を最大62%加速し、第三者の評価基準を用いてLlama-2-13Bモデルで2.84倍の全体的な高速化を達成することを示している。
詳細
引用
@article{xiao2024parallelspec,
title = {ParallelSpec: Parallel Drafter for Efficient Speculative Decoding},
author = {Xiao, Zilin and Zhang, Hongming and Ge, Tao and Ouyang, Siru and Ordonez, Vicente and Yu, Dong},
year = {2024},
journal = {arXiv preprint arXiv:2410.05589},
url = {https://arxiv.org/abs/2410.05589},
}