Going Beyond Nouns With Vision & Language Models Using Synthetic Data
보도 자료 요약
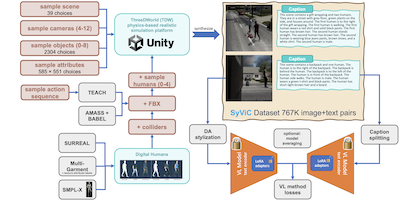
MIT, IBM, 라이스 대학교 및 여러 다른 기관의 연구자들은 CLIP과 같은 인기 있는 AI 비전-언어 모델의 지속적인 사각지대를 식별하고 그것을 고치기 위한 실용적인 한 걸음을 내디뎠다. 이러한 시스템들은 이미지 속 객체를 넘어서는 무언가를 이해하는 데 놀라울 만큼 서툴러서, 인간에게는 사소한 방식인 속성, 공간적 관계, 행동, 단어 순서를 파악하는 데 어려움을 겪는다. 이를 해결하기 위해 연구팀은 ThreeDWorld 엔진에서 물리 기반 3D 시뮬레이션을 실행하고, 무작위화된 객체, 재질, 다양한 옷을 입은 애니메이션 인간 아바타로 장면을 채운 다음, 장면 메타데이터로부터 상세한 텍스트 캡션을 자동 생성하여 SyViC — Synthetic Visual Concepts — 라는 백만 이미지 합성 데이터셋을 구축했다. 핵심 통찰은 합성 환경이 연구자들로 하여금 모델이 놓치는 바로 그 비(非)명사 개념을 의도적으로 부각하는 이미지-텍스트 쌍을 저렴하게 만들 수 있게 한다는 것인데, 이는 실세계 사진으로는 엄청나게 어렵고 비싸게 드는 일이다. 저차원 파라미터 적응(LoRA), 스타일 전이 기반 도메인 적응, 더 긴 설명 텍스트를 처리하기 위한 캡션 분할 기법을 조합하여 CLIP과 CyCLIP를 SyViC로 미세조정했을 때, 모델들은 ARO 구성적 추론 벤치마크에서 최대 9.9%, VL-Checklist 평가에서 4.3% 향상되었으며, 21개 작업에 걸쳐 제로샷 분류 정확도는 1퍼센트 미만만 희생했다. 이 연구가 중요한 이유는, 어떠한 실제 이미지도 없이 표적화된 합성 데이터만으로 대조 비전-언어 학습의 잘 기록된 구조적 약점을 유의미하게 보완할 수 있음을 입증하며, 연구팀이 데이터셋과 코드를 모두 공개했기 때문이다.
초록
대규모 사전학습 비전·언어(VL) 모델은 많은 응용에서 놀라운 성능을 보여, 지원되는 클래스의 고정된 집합을 (거의 임의의) 자연어 프롬프트에 대한 제로샷 개방형 어휘 추론으로 대체할 수 있게 했다. 그러나 최근 연구들은 이러한 모델의 근본적인 약점을 밝혀냈다. 예를 들어, 비(非)객체 단어의 의미(예: 속성, 행동, 관계, 상태 등)와 같이 '명사를 넘어서는' 시각 언어 개념(VLC)을 이해하는 데 어려움을 겪거나, 문장에서 단어 순서의 중요성을 이해하는 것과 같은 구성적 추론을 수행하는 데 어려움을 겪는다. 본 연구에서 우리는 순수하게 합성된 데이터를 어느 정도까지 활용하여 이러한 모델이 제로샷 능력을 손상시키지 않으면서 그러한 단점을 극복하도록 가르칠 수 있는지를 조사한다. 우리는 VL 모델의 VLC 이해와 구성적 추론을 향상시키기에 적합한 추가 데이터를 생성할 수 있게 하는 백만 규모의 합성 데이터셋이자 데이터 생성 코드베이스인 Synthetic Visual Concepts(SyViC)를 기여한다. 추가로, 우리는 이러한 향상을 달성하기 위해 SyViC를 효과적으로 활용하는 일반적인 VL 미세조정 전략을 제안한다. VL-Checklist, Winoground, ARO 벤치마크에 대한 우리의 광범위한 실험과 절제 연구는 강력한 사전학습 VL 모델을 합성 데이터로 적응시켜 제로샷 정확도의 1% 미만 하락만으로 그들의 VLC 이해를 크게 향상(예: ARO에서 9.9%, VL-Checklist에서 4.3%)시키는 것이 가능함을 입증한다.
세부 정보
인용
@inproceedings{cascantebonilla2023going,
title = {Going Beyond Nouns With Vision & Language Models Using Synthetic Data},
author = {Cascante-Bonilla, Paola and Shehada, Khaled and Smith, James Seale and Doveh, Sivan and Kim, Donghyun and Panda, Rameswar and Varol, Gül and Oliva, Aude and Ordonez, Vicente and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {International Conference on Computer Vision. ICCV 2023},
url = {https://arxiv.org/abs/2303.17590},
}