보도 자료 요약
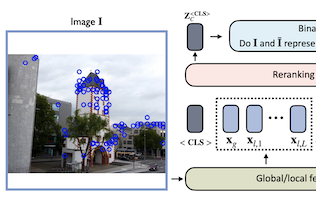
버지니아 대학교, eBay, 라이스 대학교의 연구자들은 넓은 범주가 아니라 특정 객체나 랜드마크를 식별하려는 이미지 검색 시스템의 정확도를 향상시키는 Reranking Transformer, 즉 RRT라는 경량 신경망 모델을 개발했다. 연구팀이 다룬 문제는 이미지 검색에서 흔한 2단계 과정이다. 첫 번째 단계는 컴팩트한 전역 이미지 디스크립터를 사용하여 후보 매칭의 후보 목록을 뽑아내고, 두 번째 단계는 더 상세한 국소 특징을 사용하여 그 목록을 정제하는데, 이 단계는 전통적으로 한 이미지를 다른 이미지에 맞추기 위해 기하학적으로 어떻게 변형할 수 있는지를 추정하려는 연산 집약적 기법인 기하학적 검증이 담당해 왔다. 연구자들은 그 두 번째 단계를 작은 트랜스포머 기반 모델로 대체했는데, 최근 자연어 처리의 발전을 이끈 어텐션 기반 아키텍처를 빌려와 두 이미지가 동일한 객체나 장면을 보여주는지를 직접 예측하도록 학습시켰다. 약 220만 개의 파라미터, 즉 표준 ResNet50 백본 크기의 대략 9 퍼센트에 불과하고 기하학적 검증의 절반에 해당하는 국소 특징 디스크립터만 요구하면서도, RRT는 Revisited Oxford 및 Paris 데이터셋과 Google Landmarks v2를 포함한 표준 벤치마크에서 기하학적 검증과 다른 경쟁 접근법을 능가했다. 한 가지 핵심적인 실용적 이점은 100개 후보 이미지로 이루어진 전체 후보 목록을 재순위화하는 데 네트워크를 통한 단일 순방향 패스만 소요된다는 점이다. 연구자들은 또한 기하학적 검증과 달리 RRT가 기저의 특징 추출기와 함께 공동으로 학습될 수 있어 두 구성 요소를 함께 최적화하고 추가적인 정확도 향상을 낳을 수 있음을 보였으며, 이 능력을 Stanford Online Products 데이터셋에서 입증했다.
초록
인스턴스 수준 이미지 검색은 질의 이미지 내의 객체와 일치하는 이미지를 대규모 데이터베이스에서 검색하는 작업이다. 이 작업을 해결하기 위해 시스템은 보통 전역 이미지 디스크립터를 사용하는 검색 단계와, 국소 특징에 기반한 기하학적 검증(geometric verification) 같은 연산을 활용하여 도메인별 정제나 재순위화(reranking)를 수행하는 후속 단계에 의존한다. 본 연구에서 우리는 국소 및 전역 특징을 모두 통합하여 지도학습 방식으로 매칭 이미지를 재순위화하고, 따라서 비교적 비용이 큰 기하학적 검증 과정을 대체하는 일반적 모델로서 Reranking Transformers(RRT)를 제안한다. RRT는 경량이며 쉽게 병렬화될 수 있어, 상위 매칭 결과 집합의 재순위화를 단일 순방향 패스(forward-pass)로 수행할 수 있다. 우리는 Revisited Oxford 및 Paris 데이터셋과 Google Landmarks v2 데이터셋에서 광범위한 실험을 수행하여, RRT가 훨씬 적은 수의 국소 디스크립터를 사용하면서도 이전 재순위화 접근법을 능가함을 보인다. 더 나아가, 우리는 기존 접근법과 달리 RRT가 특징 추출기와 함께 공동으로 최적화될 수 있으며, 이것이 다운스트림 작업에 맞춰진 특징 표현과 추가적인 정확도 향상으로 이어질 수 있음을 입증한다. 코드와 학습된 모델은 https://github.com/uvavision/RerankingTransformer 에서 공개적으로 이용 가능하다.
세부 정보
인용
@inproceedings{tan2021instance,
title = {Instance-level Image Retrieval using Reranking Transformers},
author = {Tan, Fuwen and Yuan, Jiangbo and Ordonez, Vicente},
year = {2021},
booktitle = {International Conference on Computer Vision. ICCV 2021},
url = {https://arxiv.org/abs/2103.12236},
}