보도 자료 요약
Meta와 라이스 대학교의 연구진은 시스템이 정확도와 속도를 필요에 따라 조정할 수 있게 하는 멀티모달 검색에 대한 새로운 접근법인 MetaEmbed를 개발했다. 텍스트와 이미지에 걸쳐 검색하는 현재의 멀티모달 검색 시스템은 정밀도와 계산 효율성 사이의 트레이드오프에 직면한다. 즉, 모든 것을 세부 정보를 잃는 단일 벡터로 압축하거나, 실용적으로 사용하기에는 너무 느려지는 수백 개의 벡터를 사용한다. MetaEmbed는 거친 정보에서 세밀한 정보까지 조직된 작은 맥락화 임베딩 집합을 만드는 학습 가능한 "Meta Token"을 도입한다. 이 설계는 사용자가 검색 시 사용할 벡터 수를 선택하여 품질과 속도 요구 사이의 균형을 맞출 수 있게 한다. 표준 벤치마크에 대한 테스트는 이 시스템이 확장하면서 최첨단 성능을 달성함을 보여준다
초록
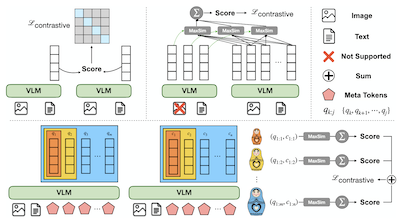
범용 멀티모달 임베딩 모델은 질의와 후보 간의 의미적 관련성을 포착하는 데 큰 성공을 거두었다. 그러나 현재의 방법들은 질의와 후보를 단일 벡터로 압축하여 세밀한 정보에 대한 표현력을 제한할 수 있거나, 다중 벡터 검색에 부담스러운 너무 많은 벡터를 생성한다. 본 연구에서 우리는 멀티모달 임베딩을 대규모로 구성하고 상호작용시키는 방식을 재고하는 새로운 멀티모달 검색 프레임워크인 MetaEmbed를 소개한다. 학습 중에는 고정된 수의 학습 가능한 Meta Token이 입력 시퀀스에 추가된다. 테스트 시점에는 이들의 마지막 계층 맥락화 표현이 간결하면서도 표현력 있는 다중 벡터 임베딩으로 사용된다. 제안된 Matryoshka Multi-Vector Retrieval 학습을 통해 MetaEmbed는 여러 벡터에 걸쳐 정보를 세분성에 따라 조직하는 법을 학습한다. 그 결과, 사용자가 인덱싱 및 검색 상호작용에 사용되는 토큰 수를 선택함으로써 검색 품질과 효율성 요구 사이의 균형을 맞출 수 있는 멀티모달 검색에서의 테스트 시점 확장이 가능해진다. Massive Multimodal Embedding Benchmark (MMEB)와 Visual Document Retrieval Benchmark (ViDoRe)에 대한 광범위한 평가는 MetaEmbed가 32B 파라미터 모델로 견고하게 확장하면서 최첨단 검색 성능을 달성함을 확인한다. 코드는 https://github.com/facebookresearch/MetaEmbed 에서 이용 가능하다.
세부 정보
인용
@inproceedings{xiao2026metaembed,
title = {MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction},
author = {Xiao, Zilin and Ma, Qi and Gu, Mengting and Chen, Chun-cheng Jason and Chen, Xintao and Ordonez, Vicente and Mohan, Vijai},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2509.18095},
}
이 논문의 자동 생성된 질문, 주요 기여 및 한계
이 논문이 답하는 데 도움이 되는 질문
- MetaEmbed란 무엇이며 어떤 문제를 다루는가? MetaEmbed는 간결한 학습 가능 Meta Token을 사용하여, 수백 개의 패치 수준 벡터가 갖는 막대한 비용 없이 단일 벡터 임베딩보다 더 표현력 있는 검색을 제공하는 멀티모달 검색 프레임워크이다.
- MetaEmbed는 어떻게 테스트 시점 확장을 가능하게 하는가? Matryoshka Multi-Vector Retrieval을 통해 중첩된 Meta Embedding 그룹을 학습하므로, 사용자는 재학습 없이 인덱싱 및 점수 산정 시점에 더 작거나 큰 검색 예산을 선택할 수 있다.
- Meta Token이 멀티모달 검색에 유용한 이유는 무엇인가? 이들의 마지막 계층 맥락화 상태는 인덱스 크기와 점수 산정 비용을 제어 가능하게 유지하면서 세밀한 질의-후보 상호작용을 보존하는 작은 다중 벡터 임베딩 집합으로 작동한다.
- MetaEmbed는 MMEB에서 얼마나 잘 수행되는가? 논문은 Qwen2.5-VL로 초기화된 MetaEmbed가 7B 모델로 전체 Precision@1 76.6, 32B 모델로 78.7을 달성하여 나열된 기준선들을 능가한다고 보고한다.
- MetaEmbed는 시각적 문서 검색에서도 작동하는가? 그렇다. 논문은 ViDoRe에서 평가하여 더 많은 Meta Embedding이 사용될수록 검색 품질이 향상되는 한편, MMR이 낮은 검색 예산에서도 강력한 성능을 보존함을 보여준다.
주요 기여
- 본 논문은 텍스트, 이미지, 혼합 모달리티 질의 및 후보 전반에 걸친 멀티모달 검색을 위한 간결한 맥락화 다중 벡터 임베딩으로서 Meta Token을 도입한다.
- Matryoshka Multi-Vector Retrieval은 거친 단계에서 세밀한 단계까지의 중첩된 임베딩 그룹을 학습하여, 단일 모델 및 인덱스 설계가 여러 품질-지연 시간 작동 지점을 지원할 수 있게 한다.
- MetaEmbed는 32B 비전-언어 모델 백본으로 확장하면서 MMEB에서 최첨단 결과를, ViDoRe에서 강력한 결과를 달성한다.
- 절제(ablation) 실험은 다중 벡터 검색의 이점이 모델 규모에 따라 커지며 MMR이 낮은 예산에서의 검색 품질을 보존하는 데 중요함을 보여준다.
- 효율성 분석은 점수 산정 지연 시간이 적당한 예산에서는 작게 유지되며, 균형 잡힌 검색 설정을 선택함으로써 인덱스 메모리를 관리할 수 있음을 보여준다.
한계 및 유의 사항
- 더 높은 검색 예산은 인덱스 메모리를 증가시키지만, 중첩 설계는 이를 고정된 배포 비용이 아니라 사용자가 제어할 수 있는 트레이드오프로 만든다.
- 가장 큰 예산은 점수 산정 FLOPs를 상당히 증가시킬 수 있으나, 측정된 지연 시간은 많은 설정에서 실용적으로 유지되며 논문은 훨씬 더 작은 예산에서도 유용한 정확도를 보여준다.
- MetaEmbed는 여전히 강력한 VLM 백본의 미세조정을 요구하므로 향후 연구에서 더 가벼운 학습 방법을 탐구할 수 있다. LoRA 설정과 다중 아키텍처 실험은 이미 이 접근법을 폭넓게 접근 가능하게 만든다.
- 평가는 표준 멀티모달 및 시각적 문서 검색 벤치마크에 초점을 맞추고 있어, 매우 큰 프로덕션 인덱스와 특화된 엔터프라이즈 도메인은 자연스러운 배포 연구 과제로 남는다.
- 이 방법은 생성이나 질의응답을 직접 목표로 하기보다 검색을 목표로 하지만, 더 나은 유연한 검색은 검색 증강 멀티모달 시스템을 위한 가치 있는 구성 요소이다.
이 결과를 읽는 방법
본 논문은 확장 가능한 멀티모달 검색에 대한 강력한 기여로 읽는 것이 가장 적절하다. MetaEmbed는 세밀한 후기 상호작용(late interaction)을 보존하고, 실용적인 테스트 시점 예산 조절 기능을 추가하며, 더 큰 VLM이 간결한 다중 벡터 인터페이스를 갖추면 더 효과적인 검색 모델이 될 수 있음을 보여준다.