Evolving Image Compositions for Feature Representation Learning
Resumo do comunicado de imprensa
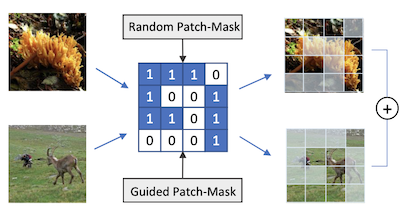
Pesquisadores da University of Virginia e da Rice University desenvolveram uma técnica de ampliação de dados chamada PatchMix que ajuda redes neurais de reconhecimento de imagens a aprender melhor ao treinar com imagens híbridas construídas artificialmente. O problema central é que modelos de deep learning para reconhecimento visual tendem a sofrer overfitting com seus dados de treinamento e, embora métodos existentes como Mixup e CutMix já misturem pares de imagens para combater isso, eles são limitados na flexibilidade com que conseguem combinar essas imagens. O PatchMix resolve isso fatiando duas imagens em uma grade de patches de tamanho igual e trocando patches entre elas de acordo com uma máscara binária, atribuindo então à imagem composta resultante um rótulo combinado proporcional a quantos patches vieram de cada fonte. A equipe também adicionou uma função de perda secundária que treina a rede para identificar corretamente a que classe cada patch individual pertence, e não apenas a imagem como um todo, o que força o modelo a construir representações mais conscientes do contexto local. Indo além, os pesquisadores usaram um algoritmo de busca genética para descobrir automaticamente quais pares de categorias de imagens são mais úteis de misturar e quais padrões de grade produzem os exemplos de treinamento mais desafiadores — e, portanto, mais informativos — tudo isso sem precisar retreinar o modelo do zero para cada configuração candidata. Testado em benchmarks padrão, um modelo ResNet-50 treinado com o PatchMix superou os modelos de base no CIFAR-10, no CIFAR-100, no Tiny ImageNet e no ImageNet, e apresentou desempenho mais forte de aprendizado por transferência em tarefas que incluem detecção de objetos, reconhecimento de cenas e legendagem de imagens, sugerindo que o método produz características visuais de propósito mais geral do que abordagens concorrentes.
resumo
Redes neurais convolucionais para reconhecimento visual exigem grandes quantidades de amostras de treinamento e geralmente se beneficiam da ampliação de dados (data augmentation). Este artigo propõe o PatchMix, um método de ampliação de dados que cria novas amostras compondo patches de pares de imagens em um padrão semelhante a uma grade. Essas novas amostras recebem pontuações de rótulo proporcionais ao número de patches emprestados de cada imagem. Em seguida, adicionamos um conjunto de perdas adicionais em nível de patch para regularizar e estimular boas representações tanto no nível de patch quanto no nível de imagem. Um modelo ResNet-50 treinado no ImageNet usando o PatchMix exibe capacidades superiores de aprendizado por transferência em uma ampla variedade de benchmarks. Embora o PatchMix possa se basear em pareamentos aleatórios e padrões de grade aleatórios para a mistura, exploramos a busca evolutiva como estratégia orientadora para descobrir conjuntamente padrões de grade e pareamentos de imagens ótimos. Para esse fim, concebemos uma função de aptidão (fitness) que dispensa a necessidade de retreinar um modelo para avaliar cada escolha possível. Dessa forma, o PatchMix supera um modelo base no CIFAR-10 (+1,91), no CIFAR-100 (+5,31), no Tiny Imagenet (+3,52) e no ImageNet (+1,16).
detalhes
citação
@inproceedings{cascantebonilla2021evolving,
title = {Evolving Image Compositions for Feature Representation Learning},
author = {Cascante-Bonilla, Paola and Sekhon, Arshdeep and Qi, Yanjun and Ordonez, Vicente},
year = {2021},
booktitle = {British Machine Vision Conference. BMVC 2021},
url = {https://arxiv.org/abs/2106.09011},
}