CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations
resumo
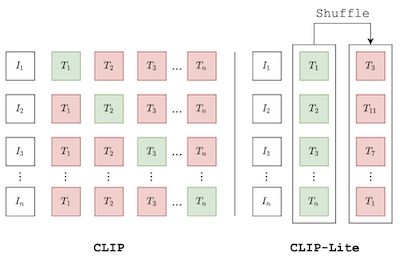
Propomos o CLIP-Lite, um método eficiente em informação para aprendizado de representações visuais por meio do alinhamento de características com anotações textuais. Em comparação com o modelo CLIP proposto anteriormente, o CLIP-Lite requer apenas um par de amostra imagem-texto negativo para cada amostra imagem-texto positiva durante a otimização de seu objetivo de aprendizado contrastivo. Conseguimos isso aproveitando um limite inferior eficiente em informação para maximizar a informação mútua entre as duas modalidades de entrada. Isso permite que o CLIP-Lite seja treinado com quantidades de dados e tamanhos de batch significativamente reduzidos, obtendo ao mesmo tempo melhor desempenho do que o CLIP na mesma escala. Avaliamos o CLIP-Lite por meio de pré-treinamento no conjunto de dados COCO-Captions e testando o aprendizado por transferência para outros conjuntos de dados. O CLIP-Lite obtém um ganho absoluto de +14,0% em mAP no desempenho na classificação do Pascal VOC e um ganho de +22,1% na acurácia top-1 no ImageNet, sendo comparável ou superior a outros modelos supervisionados por texto mais complexos. O CLIP-Lite também é superior ao CLIP na recuperação de imagens e textos, na classificação zero-shot e no visual grounding. Por fim, mostramos que o CLIP-Lite pode aproveitar a semântica da linguagem para estimular representações visuais livres de viés que podem ser usadas em tarefas downstream. Implementação: https://github.com/4m4n5/CLIP-Lite
citação
@inproceedings{shrivastava2023clip,
title = {CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations},
author = {Shrivastava, Aman and Selvaraju, Ramprasaath R. and Naik, Nikhil and Ordonez, Vicente},
year = {2023},
booktitle = {Int. Conf. on Artificial Intelligence and Statistics AISTATS 2023},
url = {https://arxiv.org/abs/2112.07133},
}