MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction
Resumo do comunicado de imprensa
Pesquisadores da Meta e da Rice University desenvolveram o MetaEmbed, uma nova abordagem para busca multimodal que permite aos sistemas ajustar sua precisão e velocidade sob demanda. Os sistemas atuais de recuperação multimodal, que buscam em textos e imagens, enfrentam um dilema entre precisão e eficiência computacional: ou comprimem tudo em um único vetor que perde detalhes, ou usam centenas de vetores que se tornam lentos demais para uso prático. O MetaEmbed introduz "Meta Tokens" aprendíveis que criam um pequeno conjunto de embeddings contextualizados organizados da informação grosseira à de granularidade fina. Esse design permite que os usuários selecionem quantos vetores usar durante a busca, equilibrando qualidade e requisitos de velocidade. Testes em benchmarks padrão mostram que o sistema atinge desempenho de ponta enquanto escala
resumo
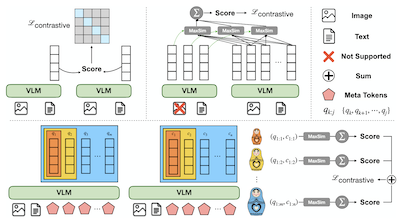
Modelos universais de embedding multimodal alcançaram grande sucesso em capturar a relevância semântica entre consultas e candidatos. No entanto, os métodos atuais ou condensam consultas e candidatos em um único vetor, potencialmente limitando a expressividade para informações de granularidade fina, ou produzem vetores em excesso que se tornam proibitivos para a recuperação multivetorial. Neste trabalho, apresentamos o MetaEmbed, um novo framework para recuperação multimodal que repensa como os embeddings multimodais são construídos e interagem em escala. Durante o treinamento, um número fixo de Meta Tokens aprendíveis é acrescentado à sequência de entrada. No momento do teste, suas representações contextualizadas da última camada servem como embeddings multivetoriais compactos, porém expressivos. Por meio do treinamento Matryoshka Multi-Vector Retrieval proposto, o MetaEmbed aprende a organizar a informação por granularidade ao longo de múltiplos vetores. Como resultado, viabilizamos o escalonamento em tempo de teste na recuperação multimodal, em que os usuários podem equilibrar a qualidade da recuperação com as demandas de eficiência ao selecionar o número de tokens usados nas interações de indexação e recuperação. Avaliações extensas no Massive Multimodal Embedding Benchmark (MMEB) e no Visual Document Retrieval Benchmark (ViDoRe) confirmam que o MetaEmbed atinge desempenho de recuperação de ponta, ao mesmo tempo em que escala de forma robusta para modelos com 32B de parâmetros. O código está disponível em https://github.com/facebookresearch/MetaEmbed.
detalhes
citação
@inproceedings{xiao2026metaembed,
title = {MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction},
author = {Xiao, Zilin and Ma, Qi and Gu, Mengting and Chen, Chun-cheng Jason and Chen, Xintao and Ordonez, Vicente and Mohan, Vijai},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2509.18095},
}
perguntas, principais contribuições e limitações deste artigo geradas automaticamente
Perguntas que este artigo ajuda a responder
- O que é o MetaEmbed e qual problema ele aborda? O MetaEmbed é um framework de recuperação multimodal que usa Meta Tokens aprendíveis e compactos para fornecer uma recuperação mais expressiva do que os embeddings de vetor único, sem o alto custo de centenas de vetores em nível de patch.
- Como o MetaEmbed viabiliza o escalonamento em tempo de teste? Ele treina grupos aninhados de Meta Embeddings por meio do Matryoshka Multi-Vector Retrieval, de modo que os usuários podem escolher orçamentos de recuperação menores ou maiores no momento da indexação e da pontuação, sem retreinamento.
- Por que os Meta Tokens são úteis para a recuperação multimodal? Seus estados contextualizados da camada final atuam como um pequeno conjunto de embeddings multivetoriais que preservam interações consulta-candidato de granularidade fina, mantendo controláveis o tamanho do índice e o custo de pontuação.
- Quão bem o MetaEmbed se sai no MMEB? O artigo relata que o MetaEmbed inicializado com Qwen2.5-VL atinge 76,6 de Precision@1 geral com um modelo de 7B e 78,7 com um modelo de 32B, superando as baselines listadas.
- O MetaEmbed funciona para recuperação de documentos visuais? Sim, o artigo avalia no ViDoRe e mostra que a qualidade da recuperação melhora à medida que mais Meta Embeddings são usados, enquanto o MMR preserva um desempenho forte com orçamentos de recuperação baixos.
Principais contribuições
- O artigo introduz os Meta Tokens como embeddings multivetoriais contextualizados e compactos para recuperação multimodal em consultas e candidatos de texto, imagem e modalidade mista.
- O Matryoshka Multi-Vector Retrieval treina grupos de embeddings aninhados do grosseiro ao fino, permitindo que um único modelo e design de índice sustentem múltiplos pontos de operação de qualidade-latência.
- O MetaEmbed alcança resultados de ponta no MMEB e resultados sólidos no ViDoRe enquanto escala para backbones de modelos de visão e linguagem de 32B.
- As ablações mostram que os benefícios da recuperação multivetorial crescem com a escala do modelo e que o MMR é importante para preservar a qualidade da recuperação em orçamentos baixos.
- A análise de eficiência mostra que a latência de pontuação permanece pequena para orçamentos moderados e que a memória do índice pode ser gerenciada com a escolha de configurações de recuperação equilibradas.
Limitações e ressalvas
- Orçamentos de recuperação maiores aumentam a memória do índice, mas o design aninhado torna isso um trade-off controlável pelo usuário, em vez de um custo fixo de implantação.
- O maior orçamento pode aumentar substancialmente os FLOPs de pontuação, mas a latência medida permanece prática para muitos cenários, e o artigo mostra uma precisão útil com orçamentos bem menores.
- O MetaEmbed ainda exige o ajuste fino de backbones de VLM robustos, então trabalhos futuros poderiam explorar receitas de treinamento mais leves; a configuração com LoRA e os experimentos multiarquitetura já tornam a abordagem amplamente acessível.
- A avaliação foca em benchmarks padrão de recuperação multimodal e de documentos visuais, deixando índices de produção muito grandes e domínios corporativos especializados como estudos naturais de implantação.
- O método visa a recuperação, e não diretamente a geração ou a resposta a perguntas, mas uma recuperação flexível e aprimorada é um componente valioso para sistemas multimodais com recuperação aumentada.
Como interpretar este resultado
Este artigo é mais bem compreendido como uma forte contribuição para a recuperação multimodal escalável: o MetaEmbed preserva a interação tardia de granularidade fina, adiciona um controle prático de orçamento em tempo de teste e mostra que VLMs maiores podem se tornar modelos de recuperação mais eficazes quando dotados de interfaces multivetoriais compactas.