ProxyThinker: Test-Time Guidance through Small Visual Reasoners
Resumo do comunicado de imprensa
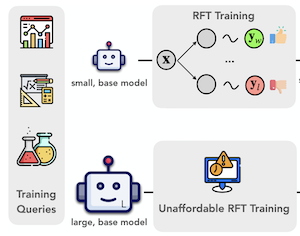
Pesquisadores da Rice University, da University of Illinois Urbana-Champaign e da University of Virginia desenvolveram um método chamado ProxyThinker que permite que grandes modelos de visão e linguagem raciocinem com mais cuidado em tempo de teste — sem qualquer treinamento adicional. O problema que se propuseram a resolver é prático: ensinar grandes modelos de IA a "desacelerar" e trabalhar em problemas visuais complexos passo a passo normalmente exige um caro ajuste fino por reforço, um processo que demanda enormes recursos computacionais e raramente foi aplicado a modelos com mais de sete bilhões de parâmetros. O ProxyThinker contorna esse custo por completo ao executar dois pequenos modelos companheiros ao lado do grande modelo durante a inferência — um que já foi ajustado para raciocinar com cuidado e outro que não foi — e usar a diferença entre suas distribuições de saída para empurrar a geração token a token do grande modelo em direção a um raciocínio mais deliberado e autoverificador. Na prática, isso significa que o grande modelo passa a exibir comportamentos como retrocesso, autoverificação e correção em múltiplos passos que, de outra forma, raramente produziria. Testando a abordagem em benchmarks padrão de matemática visual e multidisciplinares, a equipe descobriu que um modelo base de 32 bilhões de parâmetros conduzido por um especialista de raciocínio fraco de 7 bilhões de parâmetros poderia igualar ou exceder ligeiramente o desempenho de um modelo dedicado de 32 bilhões de parâmetros que havia sido totalmente ajustado com aprendizado por reforço. A equipe também desenvolveu uma implementação paralelizada sobre o arcabouço de inferência vLLM que roda cerca de 38 vezes mais rápido do que métodos anteriores de condução em tempo de decodificação, aproximando o tempo de inferência em tempo real do de simplesmente executar um único grande modelo. O trabalho é relevante porque oferece um caminho computacionalmente acessível para um raciocínio visual mais forte em grandes modelos em um momento em que os custos de treinamento do ajuste fino por reforço em escala de fronteira permanecem fora do alcance da maioria dos grupos de pesquisa.
resumo
Avanços recentes em aprendizado por reforço com recompensas verificáveis ampliaram os limites das capacidades de raciocínio visual em modelos de visão e linguagem de grande porte (LVLMs). No entanto, treinar LVLMs com ajuste fino por reforço (RFT) é computacionalmente caro, representando um desafio significativo para escalar o tamanho dos modelos. Neste trabalho, propomos o ProxyThinker, uma técnica em tempo de inferência que permite que grandes modelos herdem as capacidades de raciocínio visual de pequenos raciocinadores visuais de pensamento lento sem qualquer treinamento. Ao subtrair as distribuições de saída dos modelos base daquelas dos raciocinadores RFT, o ProxyThinker modifica a dinâmica de decodificação e elicia com sucesso o raciocínio de pensamento lento demonstrado pelos comportamentos sofisticados emergentes, como autoverificação e autocorreção. O ProxyThinker melhora de forma consistente o desempenho em benchmarks visuais desafiadores de raciocínio espacial, matemático e multidisciplinar, permitindo que modelos base não ajustados compitam com o desempenho de suas contrapartes RFT em escala completa. Além disso, nossa implementação coordena de forma eficiente múltiplos modelos de linguagem com técnicas de paralelismo e alcança uma inferência até 38 $\times$ mais rápida em comparação com métodos anteriores em tempo de decodificação, abrindo caminho para a implantação prática do ProxyThinker. O código está disponível em https://github.com/MrZilinXiao/ProxyThinker.
citação
@inproceedings{xiao2026proxythinker,
title = {ProxyThinker: Test-Time Guidance through Small Visual Reasoners},
author = {Xiao, Zilin and Koo, Jaywon and Ouyang, Siru and Hernandez, Jefferson and Meng, Yu and Ordonez, Vicente},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2505.24872},
}
perguntas, principais contribuições e limitações deste artigo geradas automaticamente
Perguntas que este artigo ajuda a responder
- O que é o ProxyThinker e qual problema ele aborda? O ProxyThinker é um método livre de treinamento em tempo de inferência que transfere o comportamento de raciocínio visual de pensamento lento de pequenos raciocinadores visuais ajustados por reforço para modelos base de visão e linguagem maiores.
- Como o ProxyThinker conduz um grande modelo? A cada passo de decodificação, ele adiciona a diferença de logits entre um pequeno especialista de raciocínio RFT e sua pequena contraparte base amadora aos logits do grande modelo base, incentivando o grande modelo a gerar tokens associados a autoverificação e raciocínio em múltiplos passos.
- Por que o método é útil em comparação com o ajuste fino por reforço completo? Ele evita atualizar os parâmetros do grande modelo, o que o torna uma alternativa prática quando o ajuste fino por reforço em escala completa de modelos de visão e linguagem de 32B ou 72B é caro demais.
- Quanto o ProxyThinker melhora os benchmarks de raciocínio visual? Em cinco benchmarks matemáticos e multidisciplinares, o ProxyThinker melhora o Qwen2.5-VL-32B em até 2,4 por cento de melhoria relativa média e o Qwen2.5-VL-72B em até 2,7 por cento de melhoria relativa média, dependendo do pequeno especialista de raciocínio.
- O ProxyThinker altera o estilo de raciocínio do grande modelo? Sim, o artigo relata mais comportamentos de retrocesso, verificação e pensamento explícito, mostrando que o método pode eliciar padrões de pensamento lento, em vez de apenas alterar as probabilidades da resposta final.
Principais contribuições
- O artigo introduz uma formulação simples em tempo de decodificação para transferência de raciocínio visual que usa o delta de logits em nível de token entre um pequeno especialista RFT e um pequeno modelo amador como orientação para um modelo base maior.
- O ProxyThinker mostra que pequenos raciocinadores visuais podem aprimorar modelos substancialmente maiores sem treinamento, incluindo modelos de visão e linguagem de 32B e 72B avaliados no MathVista, MathVerse, MathVision, MMMU-Pro e R1-OneVisionBench.
- O método permite que um modelo base Qwen2.5-VL-32B guiado por um especialista de 7B iguale ou exceda ligeiramente um modelo RFT completo de 32B em alguns cenários de benchmark, incluindo o resultado do MathVision destacado no artigo.
- A análise comportamental demonstra que o ProxyThinker pode combinar a capacidade de planejamento de submetas do grande modelo com as tendências de autoverificação e retrocesso do pequeno especialista.
- A implementação baseada em vLLM coordena múltiplos modelos de forma eficiente e relata um aumento de velocidade de 38x em relação a implementações anteriores de condução em tempo de decodificação no estilo HuggingFace, tornando a abordagem muito mais prática.
Limitações e ressalvas
- O ProxyThinker depende de ter acesso a um pequeno raciocinador visual RFT útil e ao seu modelo base amador correspondente, de modo que trabalhos futuros poderiam ampliar a receita para mais famílias de modelos e pares especialista-amador abertos.
- O método executa múltiplos modelos em tempo de inferência, o que adiciona complexidade ao sistema em comparação com uma linha de base de modelo único; a implementação vLLM otimizada do artigo reduz substancialmente essa sobrecarga e mostra que a abordagem pode ser prática.
- Os ganhos de desempenho variam entre benchmarks e especialistas, com alguns cenários apresentando melhorias menores do que outros; essa variação identifica de forma útil a seleção de especialistas e a força da orientação como ajustes importantes para futuros sistemas de raciocínio em tempo de decodificação.
- Os experimentos concentram-se em benchmarks consolidados de matemática visual e multidisciplinares, deixando cenários interativos, de longo horizonte e de implantação no mundo real como próximos testes naturais para a mesma ideia de orientação.
- O ProxyThinker conduz o comportamento de raciocínio em tempo de decodificação, em vez de alterar os pesos subjacentes do modelo, o que é uma vantagem para acessibilidade e custo, ao passo que trabalhos futuros poderiam estudar como ele complementa métodos em tempo de treinamento.
Como interpretar este resultado
Este artigo é mais bem compreendido como uma contribuição forte e prática para o raciocínio visual eficiente: o ProxyThinker mostra que pequenos raciocinadores treinados podem desbloquear um melhor comportamento de pensamento lento em modelos muito maiores em tempo de teste, oferecendo uma alternativa ou complemento convincente ao caro ajuste fino por reforço em escala completa.