Obj2Text: Generating Visually Descriptive Language from Object Layouts
Resumo do comunicado de imprensa
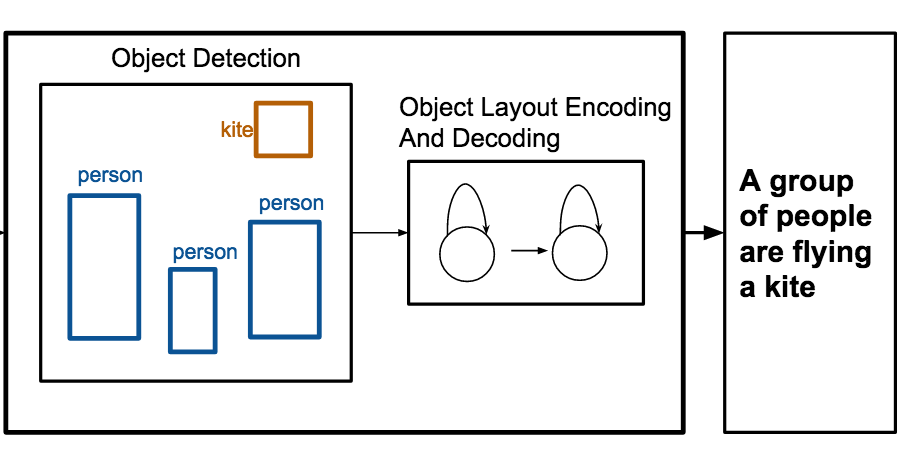
Pesquisadores da University of Virginia construíram um sistema capaz de escrever automaticamente legendas que descrevem uma cena usando nada mais do que uma lista de objetos e suas posições em uma imagem, dispensando a necessidade de dados de pixels brutos. O sistema, chamado OBJ2TEXT, funciona alimentando rótulos de objetos e suas coordenadas de caixa delimitadora em uma rede neural que codifica o layout como uma sequência, e então passando essa representação codificada a uma segunda rede neural que gera uma frase palavra por palavra. Em testes no conjunto de dados padrão de imagens MS-COCO, a equipe constatou que tanto a localização dos objetos quanto a contagem de objetos melhoraram significativamente a qualidade das legendas — remover qualquer um deles causou quedas mensuráveis no desempenho — demonstrando que mesmo uma codificação sequencial de informação espacial carrega real valor descritivo. Talvez de forma mais prática, quando os pesquisadores combinaram o OBJ2TEXT com um detector de objetos chamado YOLO e um modelo convencional de legendagem baseado em imagens, o sistema híbrido superou a linha de base de legendagem baseada apenas em imagens, elevando sua pontuação CIDEr de 0,863 para 0,950 no benchmark MS-COCO; avaliadores humanos também preferiram as legendas do sistema combinado cerca de 65 por cento das vezes quando havia consenso entre todos. O trabalho é importante porque mostra que informações estruturadas e simbólicas sobre uma cena — do tipo produzido por detectores de objetos ou usado em design gráfico e storyboarding — podem complementar ou até substituir parcialmente atributos visuais em nível de pixel na geração de linguagem, oferecendo uma maneira mais limpa de estudar o que os modelos de legendagem de imagens realmente precisam saber sobre uma cena.
resumo
Gerar legendas para imagens é uma tarefa que recentemente recebeu considerável atenção. Neste trabalho, focamos na geração de legendas para cenas abstratas, ou layouts de objetos, em que a única informação fornecida é um conjunto de objetos e suas localizações. Propomos o OBJ2TEXT, um modelo sequência-para-sequência que codifica um conjunto de objetos e suas localizações como uma sequência de entrada usando uma rede LSTM, e decodifica essa representação usando um modelo de linguagem LSTM. Mostramos que nosso modelo, apesar de codificar layouts de objetos como uma sequência, é capaz de representar relações espaciais entre objetos e gerar descrições globalmente coerentes e semanticamente relevantes. Testamos nossa abordagem em uma tarefa de geração de legendas de layout de objetos usando apenas anotações de objetos como entradas. Adicionalmente, mostramos que nosso modelo, combinado com um detector de objetos de ponta, melhora um modelo de geração de legendas de imagens de 0,863 para 0,950 (pontuação CIDEr) no benchmark de teste da tarefa padrão de legendagem MS-COCO.
detalhes
citação
@inproceedings{yin2017obj,
title = {Obj2Text: Generating Visually Descriptive Language from Object Layouts},
author = {Yin, Xuwang and Ordonez, Vicente},
year = {2017},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2017},
url = {https://arxiv.org/abs/1707.07102},
}