FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
News Release Summary
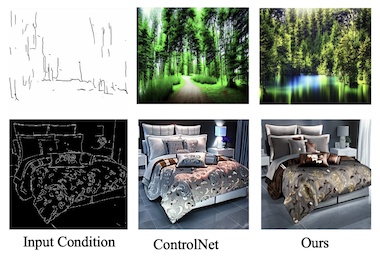
Researchers from UC Santa Cruz, Amazon, UNC Chapel Hill, Rice University, and UCLA have developed a more efficient way to control AI image generators using multiple types of visual guidance simultaneously. Current text-to-image diffusion models like Stable Diffusion can be steered by structural inputs such as edge maps, depth maps, and segmentation maps, but training these controllable systems typically demands substantial computational resources that scale up linearly as more input types are added. The team's new system, called FlexEControl, tackles this by borrowing a mathematical technique called Kronecker decomposition from the broader machine learning literature, using it to create a compact set of shared weights that handles different input modalities rather than learning separate parameters for each one. The result is a model that uses 41% fewer trainable parameters and 30% less memory than a leading comparable system called UniControlNet, while cutting training time per iteration from about 5.7 seconds to 2.1 seconds. Beyond raw efficiency, FlexEControl also performs better when juggling multiple conflicting or redundant inputs — for instance, two different edge maps of the same scene — a scenario where existing methods tend to produce muddled or incoherent images. The researchers achieved this by adding two specialized training loss functions that force the model to pay attention to the right spatial regions and align its outputs with the corresponding text prompts. In human evaluations, annotators preferred FlexEControl's outputs 64% of the time over UniControlNet's when both systems were given multiple inputs of the same type. The work matters because making controllable image generation cheaper and more capable of handling complex, mixed inputs could meaningfully broaden access to these tools for developers and researchers working with limited computing resources.
abstract
Controllable text-to-image (T2I) diffusion models generate images conditioned on both text prompts and semantic inputs of other modalities like edge maps. Nevertheless, current controllable T2I methods commonly face challenges related to efficiency and faithfulness, especially when conditioning on multiple inputs from either the same or diverse modalities. In this paper, we propose a novel Flexible and Efficient method, FlexEControl, for controllable T2I generation. At the core of FlexEControl is a unique weight decomposition strategy, which allows for streamlined integration of various input types. This approach not only enhances the faithfulness of the generated image to the control, but also significantly reduces the computational overhead typically associated with multimodal conditioning. Our approach achieves a reduction of 41% in trainable parameters and 30% in memory usage compared with Uni-ControlNet. Moreover, it doubles data efficiency and can flexibly generate images under the guidance of multiple input conditions of various modalities.
citation
@article{he2025flexecontrol,
title = {FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation},
author = {He, Xuehai and Zheng, Jian and Fang, Jacob Zhiyuan and Piramuthu, Robinson and Bansal, Mohit and Ordonez, Vicente and Sigurdsson, Gunnar A and Peng, Nanyun and Wang, Xin Eric},
year = {2025},
journal = {Transactions of Machine Learning Research, TMLR 2025.},
url = {https://arxiv.org/abs/2405.04834},
}