Learning from Synthetic Data for Visual Grounding
News Release Summary
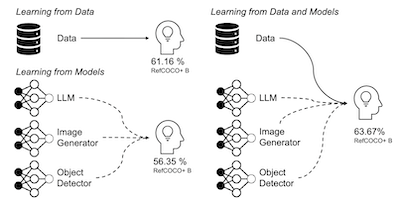
Researchers at Rice University, the University of Maryland, and UC Irvine have developed a pipeline called SynGround that automatically generates large volumes of synthetic training data to help AI systems better connect text descriptions to specific regions within images — a task known as visual grounding. The challenge they addressed is that while image-text pairs can be scraped from the web at scale, the region-level annotations needed for grounding (bounding boxes that link phrases to image areas) are expensive and slow to produce by hand; the Visual Genome dataset, a standard benchmark, took 33,000 workers six months to build. SynGround sidesteps this bottleneck by chaining together several existing pretrained models: a large multimodal model (LLaVA) captions real images in detail, those descriptions are fed to a text-to-image generator (Stable Diffusion) to create synthetic images, an LLM (Vicuna) extracts short noun phrases from the captions, and an open-vocabulary object detector (GLIP) draws bounding boxes around the referenced objects in the synthetic images. Through systematic experiments, the team found that detailed image captions produce far better synthetic images for this task than simple text concatenation or LLM-generated summaries, and that shorter extracted phrases work better than longer ones. When used to fine-tune two off-the-shelf vision-language models, ALBEF and BLIP, SynGround improved localization accuracy by 4.81 and 17.11 percentage points respectively across the RefCOCO+ and Flickr30k benchmarks; combining the synthetic data with real annotated data pushed performance even higher, surpassing the previous state of the art. The work also showed the approach can function with minimal reliance on real images and scales favorably with more data, suggesting that automated synthetic pipelines could become a practical substitute for costly human annotation in training grounding systems.
abstract
This paper extensively investigates the effectiveness of synthetic training data to improve the capabilities of vision-and-language models for grounding textual descriptions to image regions. We explore various strategies to best generate image-text pairs and image-text-box triplets using a series of pretrained models under different settings and varying degrees of reliance on real data. Through comparative analyses with synthetic, real, and web-crawled data, we identify factors that contribute to performance differences, and propose SynGround, an effective pipeline for generating useful synthetic data for visual grounding. Our findings show that SynGround can improve the localization capabilities of off-the-shelf vision-and-language models and offers the potential for arbitrarily large scale data generation. Particularly, data generated with SynGround improves the pointing game accuracy of a pretrained ALBEF and BLIP models by 4.81% and 17.11% absolute percentage points, respectively, across the RefCOCO+ and the Flickr30k benchmarks.
details
citation
@inproceedings{he2025learning,
title = {Learning from Synthetic Data for Visual Grounding},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2025},
booktitle = {British Machine Vision Conference. BMVC 2025},
url = {https://arxiv.org/abs/2403.13804},
}
automatically generated questions, main contributions and limitations of this paper
Questions this paper helps answer
- What is SynGround and what problem does it address? SynGround is a synthetic data pipeline for visual grounding that generates image-text-box triplets to reduce reliance on expensive human region annotations.
- How does SynGround generate training data? It uses an image description model to produce detailed captions, a text-to-image generator to synthesize images, an LLM to extract short grounding phrases, and an open-vocabulary detector to produce boxes for those phrases.
- Why are detailed captions important in the pipeline? The experiments show that detailed Image2Text captions produce more useful synthetic images for grounding than simple caption concatenation or Text2Text summaries.
- How much does SynGround improve visual grounding? Synthetic data from SynGround improves ALBEF by 4.81 percentage points and BLIP by 17.11 percentage points on average across RefCOCO+ and Flickr30k pointing-game evaluations.
- Can SynGround reduce dependence on real images? Yes, the paper reports variants with much less reliance on real images and shows that synthetic data outperforms comparable web-crawled data for visual grounding.
Main contributions
- The paper provides a systematic study of how to synthesize useful image-text and image-text-box data for visual grounding rather than only demonstrating one synthetic-data recipe.
- SynGround combines strong pretrained models for captioning, image generation, phrase extraction, and open-vocabulary detection into a practical pipeline for scalable grounding supervision.
- The experiments identify concrete design choices that matter, including detailed image descriptions for generation and shorter extracted phrases for grounding supervision.
- The paper shows that synthetic triplets can improve two different vision-language models, ALBEF and BLIP, supporting the generality of the approach beyond one architecture.
- The comparison with Conceptual Captions web-crawled data shows that targeted synthetic data can be more effective for grounding than simply scaling generic image-text data.
Limitations and cautions
- SynGround inherits some limitations from the pretrained captioners, image generators, LLMs, and detectors it uses, but that also means the pipeline can improve naturally as those component models get stronger.
- Synthetic boxes and captions do not fully match the precision and diversity of human Visual Genome annotations, yet the performance gains show that they are already useful enough to reduce annotation pressure substantially.
- Some generated people or scenes can contain visual artifacts, which is a known issue for synthetic image generation; the grounding improvements suggest the pipeline remains effective despite occasional imperfect samples.
- The study focuses mainly on pointing-game style visual grounding with ALBEF and BLIP, leaving phrase-box prediction systems and newer multimodal architectures as promising follow-up targets.
- The pipeline has multiple stages and design choices, but the paper's ablations make those choices interpretable and provide a strong practical recipe for future synthetic grounding datasets.
How to read this result
This paper is best read as a strong empirical case for synthetic supervision in visual grounding: SynGround shows that carefully generated image-text-box triplets can meaningfully improve localization, augment real data, and offer a scalable path beyond expensive human region annotation.