Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation
News Release Summary
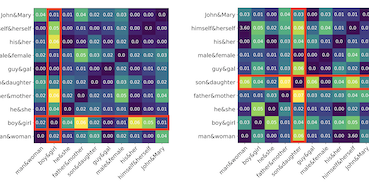
Researchers from the University of Virginia and Salesforce Research have identified a previously overlooked factor that undermines common techniques for removing gender bias from word embeddings — the statistical frequency of words in training data. Word embeddings, the numerical representations of language used in countless AI and natural language processing applications, are known to encode societal gender stereotypes, such as associating "programmer" with men and "homemaker" with women. The dominant fix for this problem, an algorithm called Hard Debias, works by identifying and projecting out a "gender direction" from the embedding space, but the researchers found that word frequency information baked into embeddings distorts that gender direction before it can be cleanly removed. To address this, they built a two-step method called Double-Hard Debias, which first strips out the frequency-related component of the embeddings and then applies the standard Hard Debias procedure. Testing on GloVe and Word2Vec embeddings across three standard bias benchmarks — including a coreference resolution task, a word association test, and a clustering-based geometry check — their approach reduced measurable gender bias more substantially than previous methods, with the gap between how well a coreference system performed on gender-stereotypical versus counter-stereotypical sentences dropping from 15.2 percentage points with unmodified GloVe to just 0.9 with their method, while general language quality on word analogy and categorization tasks remained largely intact. The work suggests that cleaning up word embeddings requires paying closer attention to the structural artifacts that corpus statistics leave behind.
abstract
Word embeddings derived from human-generated corpora inherit strong gender bias which can be further amplified by downstream models. Some commonly adopted debiasing approaches, including the seminal Hard Debias algorithm, apply post-processing procedures that project pre-trained word embeddings into a subspace orthogonal to an inferred gender subspace. We discover that semantic-agnostic corpus regularities such as word frequency captured by the word embeddings negatively impact the performance of these algorithms. We propose a simple but effective technique, Double Hard Debias, which purifies the word embeddings against such corpus regularities prior to inferring and removing the gender subspace. Experiments on three bias mitigation benchmarks show that our approach preserves the distributional semantics of the pre-trained word embeddings while reducing gender bias to a significantly larger degree than prior approaches.
details
citation
@inproceedings{wang2020double,
title = {Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation},
author = {Wang, Tianlu and Lin, Xi Victoria and Rajani, Nazneen Fatema and McCann, Bryan and Ordonez, Vicente and Xiong, Caiming},
year = {2020},
booktitle = {Association for Computational Linguistics. ACL 2020},
url = {https://arxiv.org/abs/2005.00965},
}