AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
Краткое изложение пресс-релиза
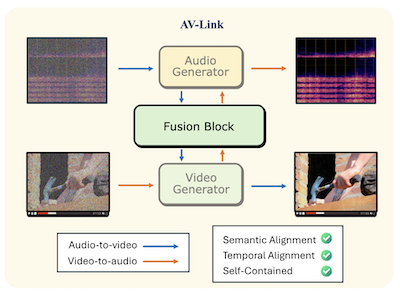
Исследователи из Rice University и Snap Inc. разработали систему под названием AV-Link, которая может генерировать синхронизированное аудио из беззвучного видео или генерировать видео под заданный аудиоклип, используя единый унифицированный фреймворк вместо отдельных специализированных инструментов, доминировавших в этой области. Основная проблема, над которой работала команда, — временное согласование: добиться, чтобы сгенерированный вывод действительно синхронизировался с событиями в исходном материале, так чтобы, например, удар барабана приходился точно на момент попадания барабанной палочки, а не просто звучал смутно похоже на барабан. Большинство существующих подходов опираются на предобученные экстракторы признаков вроде CLIP или ImageBind, чтобы извлечь семантический смысл из одной модальности и передать его генератору для другой, но эти экстракторы никогда не проектировались с учётом точного тайминга. Вместо этого AV-Link напрямую подключается к внутренним активациям замороженных предобученных диффузионных моделей аудио и видео, которые, как обнаружили исследователи, уже содержат богатую временную информацию как побочный продукт обучения генерации меняющихся во времени сигналов. Лёгкий модуль под названием Fusion Block — добавляющий примерно 186 миллионов параметров поверх замороженных базовых моделей — соединяет два генератора через общую операцию self-attention со специально разработанным rotary position embedding, который выравнивает токены аудио и видео в единую временную систему отсчёта. На стандартном бенчмарке VGGSounds система улучшила точность onset — меру того, насколько хорошо звуковые события совпадают с визуальными — на величину до 76 процентов по сравнению с лучшей конкурирующей базовой моделью, а в пользовательских исследованиях её предпочитали гораздо более крупной модели MovieGen Audio от Meta по временному согласованию в 63,6 процента случаев. Практическая значимость в том, что одна компактная система могла бы справляться с генерацией text-to-audio, text-to-video, video-to-audio и audio-to-video, потенциально упрощая производственные пайплайны для приложений — от автоматизированной постобработки кино до AI-генерируемых медиа.
аннотация
Мы предлагаем AV-Link — единый фреймворк для генерации Video-to-Audio (A2V) и Audio-to-Video (A2V), который использует активации замороженных диффузионных моделей видео и аудио для временно-согласованного кросс-модального кондиционирования. Ключом к нашему фреймворку является Fusion Block, который обеспечивает двунаправленный обмен информацией между диффузионными моделями видео и аудио посредством временно-согласованных операций self-attention. В отличие от предшествующих работ, использующих отдельные модели для задач A2V и V2A и опирающихся на предобученные экстракторы признаков, AV-Link решает обе задачи в едином самодостаточном фреймворке, напрямую используя признаки, полученные из дополняющей модальности (т. е. видеопризнаки для генерации аудио или аудиопризнаки для генерации видео). Обширные автоматические и субъективные оценки демонстрируют, что наш метод достигает существенного улучшения в синхронизации аудио и видео, превосходя более дорогостоящие базовые модели, такие как модель video-to-audio MovieGen.
подробности
цитирование
@inproceedings{hajiali2025av,
title = {AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Skorokhodov, Ivan and Canberk, Alper and Lee, Kwot Sin and Ordonez, Vicente and Tulyakov, Sergey},
year = {2025},
booktitle = {International Conference on Computer Vision. ICCV 2025},
url = {https://arxiv.org/abs/2412.15191},
}