Improved Visual Grounding through Self-Consistent Explanations
Краткое изложение пресс-релиза
Исследователи из Rice University и UC Irvine разработали технику, помогающую системам искусственного интеллекта более надёжно определять местоположение объектов на изображениях по текстовому описанию — задача, известная как визуальная локализация. Основная проблема, которую они решали, заключается в том, что существующие модели зрения и языка, обучающиеся сопоставлять изображения с текстом, могут правильно локализовать объект вроде «frisbee», но дают сбой, когда тот же объект описывается другим словом, например «disc». Чтобы исправить это, команда создала подход к обучению под названием SelfEQ (Self-consistency EQuivalence Tuning), который использует большую языковую модель для автоматической генерации парафраз подписей к изображениям, а затем дообучает визуальную модель так, чтобы и исходная фраза, и её парафраз выделяли одну и ту же область на изображении. Метод работает без необходимости каких-либо аннотаций в виде ограничивающих рамок, опираясь вместо этого на градиентные карты визуального объяснения — в частности GradCAM — как форму слабого контроля. Протестированный на трёх стандартных бенчмарках, SelfEQ улучшил точность локализации на 4,69 процентного пункта на Flickr30k, на 7,68 пункта на ReferIt и в среднем на 3,74 пункта на RefCOCO+, превзойдя большинство других методов, которые также обходятся без контроля с помощью ограничивающих рамок, и даже соперничая с некоторыми, которые их используют. Практический итог — модель, которая обрабатывает более широкий словарь и локализует объекты более согласованно, что является полезным прогрессом для таких приложений, как визуальный поиск и взаимодействие человека с машиной, которые зависят от связывания языка с конкретными частями изображения.
аннотация
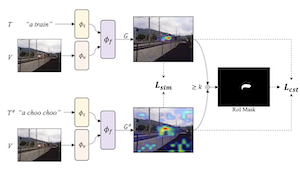
Модели зрения и языка, обученные сопоставлять изображения с текстом, можно сочетать с методами визуального объяснения, чтобы указывать на местоположения конкретных объектов на изображении. Наша работа показывает, что способности этих моделей к локализации — «grounding» — можно дополнительно улучшить путём дообучения для самосогласованных визуальных объяснений. Мы предлагаем стратегию дополнения существующих наборов данных текст-изображение парафразами с помощью большой языковой модели, а также SelfEQ — слабо контролируемую стратегию на картах визуальных объяснений для парафраз, которая поощряет самосогласованность. В частности, для входной текстовой фразы мы пытаемся сгенерировать парафраз и дообучить модель так, чтобы фраза и парафраз соответствовали одной и той же области на изображении. Мы полагаем, что это одновременно расширяет словарь, который способна обрабатывать модель, и повышает качество локализаций объектов, выделяемых градиентными методами визуального объяснения (например, GradCAM). Мы демонстрируем, что SelfEQ повышает производительность на Flickr30k, ReferIt и RefCOCO+ по сравнению с сильным базовым методом и несколькими предыдущими работами. В частности, по сравнению с другими методами, которые не используют какие-либо аннотации в виде рамок, мы получаем 84,07% на Flickr30k (абсолютное улучшение на 4,69%), 67,40% на ReferIt (абсолютное улучшение на 7,68%) и 75,10%, 55,49% на тестовых наборах A и B RefCOCO+ соответственно (абсолютное улучшение в среднем на 3,74%).
подробности
цитирование
@inproceedings{he2024improved,
title = {Improved Visual Grounding through Self-Consistent Explanations},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2024},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2024},
url = {https://arxiv.org/abs/2312.04554},
}
автоматически сгенерированные вопросы, основные вклады и ограничения этой статьи
Вопросы, на которые помогает ответить эта статья
- Какую проблему решает SelfEQ? SelfEQ улучшает визуальную локализацию, заставляя модель зрения и языка локализовать эквивалентные фразы, такие как «frisbee» и «disc», в одну и ту же область изображения.
- Как метод работает без контроля с помощью ограничивающих рамок? Он использует карты объяснений GradCAM от существующей модели зрения и языка в качестве слабого контроля, а затем обучает модель так, чтобы исходная фраза и её парафраз создавали согласованные карты локализации.
- Почему парафразы, сгенерированные LLM, здесь полезны? Парафразы расширяют формулировки, которые способна обрабатывать модель, и создают пары эквивалентности, которые учат модель согласованно локализовать семантически схожие описания.
- Какова роль целевой функции SelfEQ? Целевая функция сочетает сходство тепловых карт с членом согласованности области интереса, так что парафразированные запросы пространственно совпадают, избегая при этом тривиальных однородных карт объяснений.
- Какие бенчмарки демонстрируют влияние метода? В статье сообщается об улучшениях на Flickr30k, ReferIt и RefCOCO+, включая сильные результаты среди методов, которые не используют аннотации в виде рамок.
Основные вклады
- В статье представлен Self-consistency EQuivalence Tuning — слабо контролируемая целевая функция для улучшения визуальной локализации через согласованные объяснения для парафразированного текста.
- Она показывает, что сгенерированные LLM парафразы можно использовать в качестве масштабируемых обучающих сигналов для визуальной локализации, превращая лингвистическую эквивалентность в полезный пространственный контроль.
- Метод улучшает пайплайн локализации на основе ALBEF, не требуя ограничивающих рамок, масок сегментации, детекторов объектов или сетей предложения рамок.
- SelfEQ достигает существенного прироста по сравнению с сильными слабо контролируемыми базовыми моделями, включая 84,07% на Flickr30k, 67,40% на ReferIt и улучшенную точность в pointing-game на RefCOCO+.
- Абляционные исследования проясняют, почему явная настройка эквивалентности имеет значение: простое добавление парафраз в качестве дополнительных пар изображение-текст менее эффективно, чем прямое обеспечение самосогласованных визуальных объяснений.
Ограничения и предостережения
- SelfEQ разработан для слабо контролируемой локализации с картами объяснений, поэтому он дополняет, а не заменяет полностью контролируемые системы локализации, когда доступны высококачественные рамки.
- Метод зависит от качества сгенерированных парафраз, но в статье используется ясная стратегия формирования запросов и фильтрации и показано, что получаемые пары эквивалентности обеспечивают практический прирост.
- Поскольку он основан на объяснениях в стиле GradCAM от базовой модели зрения и языка, производительность может отражать сильные стороны лежащей в основе модели; это делает SelfEQ особенно ценным в качестве стратегии настройки для улучшения существующих моделей.
- Оценка сосредоточена на стандартных бенчмарках локализации и точности в pointing-game, оставляя более широкие реальные сценарии визуального поиска, робототехники и доступности в качестве естественных следующих приложений.
- Подход сосредоточен на локализации фраз и областей, а не на полном открытом визуальном рассуждении, что делает вклад чётко сфокусированным и облегчает интерпретацию заявленного прироста.
Как интерпретировать этот результат
Эту статью лучше всего воспринимать как сильный вклад в слабо контролируемую визуальную локализацию: SelfEQ превращает согласованность парафраз в практический обучающий сигнал, улучшая точность локализации и устойчивость к словарю без необходимости в дорогостоящих аннотациях местоположения объектов.