Estimating and Maximizing Mutual Information for Knowledge Distillation
Tóm tắt thông cáo báo chí
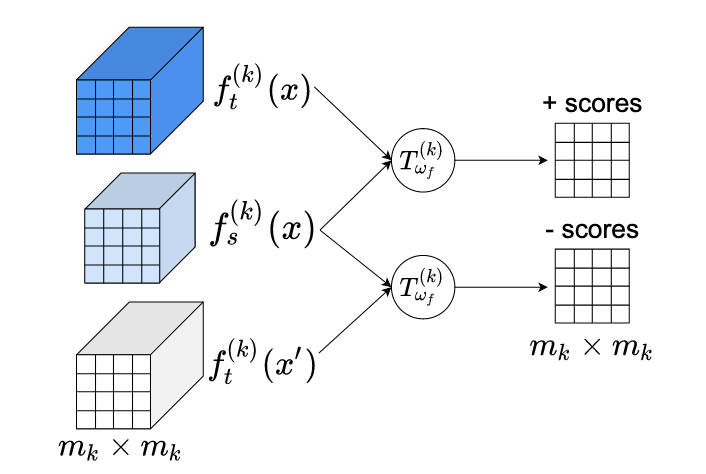
Các nhà nghiên cứu tại University of Virginia và Rice University đã phát triển một kỹ thuật mới để thu nhỏ các mô hình trí tuệ nhân tạo lớn xuống các kích thước có thể chạy trên điện thoại và các thiết bị bị giới hạn tài nguyên khác, mà không hy sinh quá nhiều độ chính xác của chúng. Thách thức cốt lõi trong lĩnh vực này, được gọi là chưng cất tri thức (knowledge distillation), là làm cho một mạng nơ-ron "trò" nhỏ hơn hấp thụ được thông tin hữu ích từ một mạng "thầy" lớn hơn, có năng lực hơn. Các phương pháp hiện có thường làm điều này bằng cách khớp các đầu ra hoặc các biểu diễn trung gian của hai mạng bằng các độ đo khoảng cách đơn giản, điều này có thể gặp khó khăn khi mạng thầy và mạng trò có các kiến trúc nội tại rất khác nhau. Khung làm việc mới, gọi là MIMKD (Mutual Information Maximization Knowledge Distillation), áp dụng một cách tiếp cận khác bằng cách sử dụng một mục tiêu Contrastive Learning bắt nguồn từ lý thuyết thông tin — cụ thể là một bộ ước lượng dựa trên phân kỳ Jensen-Shannon — để đồng thời ước lượng và tối đa hóa thông tin tương hỗ được chia sẻ giữa các biểu diễn của hai mạng, cả ở cấp độ các đặc trưng toàn cục cuối cùng lẫn ở các cấp độ đặc trưng cục bộ và trung gian tinh tế hơn. Một lợi thế thực tiễn là công thức này, không giống như các phương pháp cạnh tranh như Contrastive Representation Distillation, chỉ đòi hỏi một mẫu tiêu cực duy nhất trong quá trình huấn luyện thay vì hàng nghìn mẫu, khiến nó tốn ít bộ nhớ hơn nhiều và áp dụng được nhiều hơn cho các lớp mạng trung gian. Trong các thử nghiệm trên các benchmark phân loại ảnh CIFAR-100 và ImageNet, MIMKD liên tục vượt trội hơn các lựa chọn thay thế đã được thiết lập qua một loạt các cặp thầy-trò, bao gồm các trường hợp mà hai mạng có thiết kế rất khác nhau, nâng độ chính xác của một ShuffleNetV2 lên gần 5 điểm phần trăm bằng cách sử dụng một mạng thầy ResNet-50 và cải thiện một ResNet-18 trên ImageNet lên 1.44 điểm phần trăm so với cơ sở của nó — những kết quả gợi ý rằng cách tiếp cận này có thể giúp làm cho các mô hình AI có năng lực trở nên thực tiễn hơn để triển khai ở biên (edge).
tóm tắt
Trong công trình này, chúng tôi đề xuất Mutual Information Maximization Knowledge Distillation (MIMKD). Phương pháp của chúng tôi sử dụng một mục tiêu tương phản để đồng thời ước lượng và tối đa hóa một cận dưới của thông tin tương hỗ giữa các biểu diễn đặc trưng cục bộ và toàn cục giữa một mạng thầy và một mạng trò. Chúng tôi chứng minh qua các thí nghiệm rộng rãi rằng điều này có thể được sử dụng để cải thiện hiệu năng của các mô hình có dung lượng thấp bằng cách chuyển giao tri thức từ các mô hình có hiệu năng cao hơn nhưng tốn kém về mặt tính toán. Điều này có thể được sử dụng để tạo ra các mô hình tốt hơn có thể chạy trên các thiết bị có tài nguyên tính toán thấp. Phương pháp của chúng tôi linh hoạt, chúng tôi có thể chưng cất tri thức từ các mạng thầy với kiến trúc mạng tùy ý sang các mạng trò tùy ý. Các kết quả thực nghiệm của chúng tôi cho thấy MIMKD vượt trội hơn các cách tiếp cận cạnh tranh qua một loạt các cặp trò-thầy với các dung lượng khác nhau, với các kiến trúc khác nhau, và khi các mạng trò có dung lượng cực thấp. Chúng tôi có thể đạt được độ chính xác 74.55% trên CIFAR100 với một ShufflenetV2 từ độ chính xác cơ sở là 69.8% bằng cách chưng cất tri thức từ ResNet-50. Trên Imagenet, chúng tôi cải thiện một mạng ResNet-18 từ độ chính xác 68.88% lên 70.32% (1.44%+) bằng cách sử dụng một mạng thầy ResNet-34.
trích dẫn
@inproceedings{shrivastava2023estimating,
title = {Estimating and Maximizing Mutual Information for Knowledge Distillation},
author = {Shrivastava, Aman and Qi, Yanjun and Ordonez, Vicente},
year = {2023},
booktitle = {Workshop on Fair, Data Efficient and Trusted Computer Vision at CVPR 2023},
url = {https://arxiv.org/abs/2110.15946},
}