ParallelSpec: Parallel Drafter for Efficient Speculative Decoding
Tóm tắt thông cáo báo chí
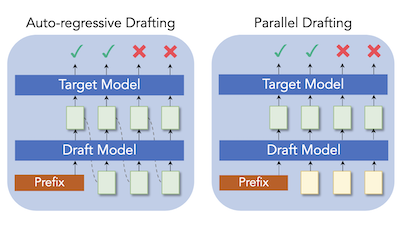
Các nhà nghiên cứu tại Rice University và Tencent AI Lab đã phát triển một kỹ thuật mới mang tên ParallelSpec giúp tăng tốc một phương pháp phổ biến để làm cho suy luận mô hình ngôn ngữ lớn nhanh hơn. Thách thức cơ bản là các hệ thống được gọi là speculative decoding — vốn sử dụng một mô hình "phác thảo" nhỏ để nhanh chóng đề xuất văn bản ứng viên mà một mô hình mục tiêu lớn hơn sau đó kiểm tra song song — vẫn buộc mô hình phác thảo nhỏ đó sinh từng token một, tạo ra một nút thắt cổ chai ngày càng dài hơn khi mô hình phác thảo được yêu cầu dự đoán càng nhiều token. Để khắc phục điều này, nhóm nghiên cứu xây dựng một mô hình phác thảo nhẹ duy nhất dự đoán nhiều token tương lai đồng thời trong một lượt truyền xuôi, sử dụng các token "mask" giữ chỗ được huấn luyện đặc biệt để thúc đẩy mô hình nhìn về phía trước mà không chạy tuần tự. Họ cũng thiết kế một quy trình huấn luyện cẩn thận, gọi là huấn luyện song song theo nhóm (group-wise parallel training), để ngăn các sai lệch giữa cách mô hình được huấn luyện và cách nó thực sự chạy khi suy luận. Khi được cắm vào hai khung speculative decoding đã được thiết lập, Medusa và EAGLE, cách tiếp cận này mang lại các mức tăng tốc nhất quán trên một loạt các tác vụ sinh văn bản bao gồm dịch thuật, tóm tắt, suy luận toán học, và trả lời câu hỏi; trên Llama-2-13B nó đạt 2.84 lần tốc độ của sinh tự hồi quy tiêu chuẩn, và nó nâng mức tăng tốc của Medusa trên Vicuna-7B lên khoảng 63 phần trăm. Công trình này quan trọng vì nó giải quyết một sự kém hiệu quả cơ bản trong giai đoạn phác thảo thay vì chỉ đơn giản điều chỉnh số lượng token được đề xuất, có khả năng làm cho việc tăng tốc LLM không mất mát trở nên thực tiễn hơn cho các ứng dụng thời gian thực.
tóm tắt
Speculative decoding đã được chứng minh là một giải pháp hiệu quả cho suy luận mô hình ngôn ngữ lớn (LLM), trong đó bộ phác thảo (drafter) nhỏ dự đoán các token tương lai với chi phí thấp, và mô hình mục tiêu được tận dụng để xác minh chúng song song. Tuy nhiên, hầu hết các công trình hiện có vẫn phác thảo token theo kiểu tự hồi quy để duy trì sự phụ thuộc tuần tự trong mô hình hóa ngôn ngữ, điều mà chúng tôi cho là một gánh nặng tính toán khổng lồ trong speculative decoding. Chúng tôi trình bày ParallelSpec, một giải pháp thay thế cho các chiến lược phác thảo tự hồi quy trong các cách tiếp cận speculative decoding tốt nhất hiện nay. Khác với phác thảo tự hồi quy trong giai đoạn suy đoán, chúng tôi huấn luyện một bộ phác thảo song song để phục vụ như một mô hình suy đoán hiệu quả. ParallelSpec học cách dự đoán hiệu quả nhiều token tương lai song song bằng một mô hình duy nhất, và nó có thể được tích hợp vào bất kỳ khung speculative decoding nào đòi hỏi căn chỉnh các phân phối đầu ra của bộ phác thảo và mô hình mục tiêu với chi phí huấn luyện tối thiểu. Các kết quả thí nghiệm cho thấy ParallelSpec tăng tốc các phương pháp baseline về độ trễ tới 62% trên các benchmark sinh văn bản từ nhiều miền khác nhau, và nó đạt mức tăng tốc tổng thể 2.84X trên mô hình Llama-2-13B sử dụng các tiêu chí đánh giá của bên thứ ba.
chi tiết
trích dẫn
@article{xiao2024parallelspec,
title = {ParallelSpec: Parallel Drafter for Efficient Speculative Decoding},
author = {Xiao, Zilin and Zhang, Hongming and Ge, Tao and Ouyang, Siru and Ordonez, Vicente and Yu, Dong},
year = {2024},
journal = {arXiv preprint arXiv:2410.05589},
url = {https://arxiv.org/abs/2410.05589},
}