Taming Data and Transformers for Audio Generation
新闻稿摘要
来自莱斯大学和 Snap Inc. 的研究人员攻克了 AI 生成环境声音中一个长期存在的瓶颈——缺乏大规模、标注良好的训练数据,以及模型在规模增大时无法相应改进。为解决数据问题,团队开发了一个自动化流程,通过识别没有语音或音乐转录的片段,从现有的基于 YouTube 的视频数据集中挖掘环境音频片段,从而避免了下载原始视频并在其上运行昂贵分类器的需要。其成果是 AutoReCap-XL,一个包含 4700 万个带文本描述的环境音频片段的数据集,大约是此前可用数据规模的 75 倍。为生成这些描述,他们构建了 AutoCap,一个音频字幕生成模型,它在 Q-Former 模块之外还融入了视频标题和帧级字幕等视觉元数据,在标准的 AudioCaps 基准上达到了 83.2 的 CIDEr 分数——比先前方法提升了 3.2%。在生成方面,他们提出了 GenAu,一个扩展到 12.5 亿参数的基于 transformer 的扩散模型,它借鉴了最初为视频设计的 "FIT" 架构,利用局部和全局注意力层将算力集中在信息丰富的音频片段上,而非在静音或冗余部分均匀分摊。与可比基线相比,GenAu 将 Inception Score 提升了 11.1%,将 Fréchet Audio Distance 提升了 4.7%,将 CLAP 文本对齐分数提升了 13.5%,并且——与先前的大型音频模型不同——随着模型规模和数据集规模的增大而持续稳定改进,这表明该领域或许终于有了一个像图像和视频生成那样扩展环境声音生成的方法。
摘要
环境声音生成器的可扩展性受制于数据稀缺、字幕质量不足以及模型架构的扩展能力有限。本工作通过推进数据和模型两方面的扩展来应对这些挑战。首先,我们提出了一个专为环境音频生成量身定制的高效且可扩展的数据集收集流程,由此得到了 AutoReCap-XL——拥有超过 4700 万个片段的最大环境音频-文本数据集。为提供高质量的文本标注,我们提出了 AutoCap,一个高质量的自动音频字幕生成模型。通过采用 Q-Former 模块并利用音频元数据,AutoCap 大幅提升了字幕质量,达到了 $83.2$ 的 CIDEr 分数,比先前的字幕生成模型提升了 $3.2\%$。最后,我们提出了 GenAu,一种可扩展的基于 transformer 的音频生成架构,并将其扩展到 12.5 亿参数。我们展示了它在使用合成字幕进行数据扩展以及模型规模扩展两方面的优势。与在相近规模和数据规模下训练的基线音频生成器相比,GenAu 取得了显著改进:FAD 分数提升 $4.7\%$,IS 提升 $11.1\%$,CLAP 分数提升 $13.5\%$。我们的代码、模型检查点和数据集均已公开。
详情
引用
@article{hajiali2026taming,
title = {Taming Data and Transformers for Audio Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Balakrishnan, Guha and Ordonez, Vicente},
year = {2026},
journal = {International Journal of Computer Vision. IJCV 2026},
url = {https://arxiv.org/abs/2406.19388},
}
自动生成的本文相关问题、主要贡献与局限
本文有助于回答的问题
- 这篇论文解决了什么问题?它针对可扩展环境声音生成的主要障碍:稀缺的音频-文本数据、薄弱的字幕质量,以及未能可靠地从扩展中获益的生成器架构。
- 什么是 AutoReCap-XL?AutoReCap-XL 是一个超大规模的环境音频-文本数据集,包含超过 4700 万个片段,通过对在线视频片段筛选出非语音、非音乐音频并自动重新生成字幕而收集得到。
- 什么是 AutoCap?AutoCap 是一个自动音频字幕生成模型,它结合了音频特征、Q-Former、BART 解码以及视频标题和视觉字幕等元数据,以生成更高质量的音频描述。
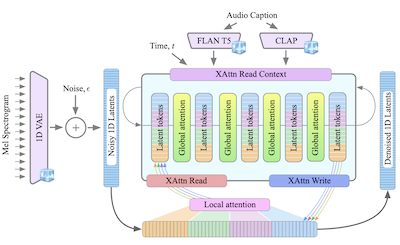
- 什么是 GenAu?GenAu 是一个用于文本到音频生成的基于 transformer 的潜在扩散模型,它将 FIT 风格架构与局部和全局注意力相结合,以适应音频的时序结构。
- 为什么扩展在这项工作中很重要?论文表明,GenAu 随着更多合成字幕数据和更大模型规模而改进,这一点很重要,因为早期的环境音频生成器往往表现出薄弱或不一致的扩展行为。
主要贡献
- 论文引入了 AutoReCap-XL,在文中被描述为最大的环境音频-文本数据集,包含 4700 万个片段、约 12.35 万小时的音频,取自大规模视频源。
- 它提出了 AutoCap,一个强大的音频字幕生成器,利用 Q-Former 和元数据来提升字幕质量,在 AudioCaps 上达到 83.2 的 CIDEr 分数。
- 它提出了 GenAu,一个可扩展的基于 transformer 的文本到音频扩散架构,使用 1D VAE 潜在空间和受 FIT 启发的局部/全局注意力以实现高效的音频生成。
- 实验表明相比可比的文本到音频基线有明显改进,包括在 FAD、Inception Score 和 CLAP 对齐方面的提升。
- 论文通过同时改进数据集、字幕生成流程和模型架构,而非将它们视为各自独立的问题,为环境音频生成提供了一份异乎寻常完整的扩展方案。
局限与注意事项
- AutoCap 是在 AudioCaps 上微调的,其词汇量有限,因此非常细致或不寻常的提示可能仍具挑战性;论文将此视为未来改进字幕生成器和数据集的一条直接路径。
- AutoReCap-XL 主要通过音频生成实验进行验证,这是一个有力的首个用例,同时将音频检索、音频理解和音视频任务留作有前景的扩展方向。
- 数据收集流程依赖于转录、元数据和筛选启发式方法,但这也正是使其足够高效以扩展到远超手动标注环境音频数据集的原因。
- GenAu 针对的是环境声音,而非语音或音乐生成,这使论文有了聚焦的贡献,同时将相关音频领域留作自然的适配机会。
- 大规模训练和一个 12.5 亿参数的模型需要可观的算力,但结果有力地表明,这一投入为环境音频生成带来了更好的扩展行为。
如何理解这一结果
这篇论文最好被理解为环境音频生成在系统层面上的一项重大进展:通过将一个海量的重新标注数据集、一个更强的字幕生成模型和一个可扩展的 transformer 扩散生成器相结合,它为该领域提供了一套通过数据和模型扩展来提升文本到音频质量的实用方案。