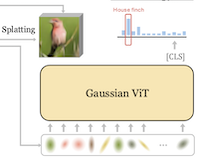
新闻稿摘要
莱斯大学和 UC Irvine 的研究人员构建了一种新的图像分类系统,它抛弃了向神经网络输入像素网格或矩形图块的传统做法,转而以一组紧凑的、被称为二维高斯函数(2D Gaussians)的数学斑块来替代这种输入。该系统名为 GViT,其工作方式是训练一个小型编码器网络,用数百个高斯函数来描述每幅图像,其中每个斑块都携带有关其位置、大小、朝向、颜色和不透明度的信息。训练设置的巧妙之处在于,分类模型与高斯编码器在一个反馈回路中协同训练:来自分类器的梯度——本质上是关于图像哪些部分对识别其内容重要的信号——被反馈回去,引导高斯函数趋向真正有助于识别的区域,而不是让它们均匀地铺散在无信息量的背景上。在标准 ImageNet-1k 基准上采用这一方法,GViT 的最佳版本在 ViT-Base 架构下达到 76.9% 的 top-1 准确率,而同等规模的传统基于图块的 ViT 约为 78.7%——在使用一种根本不同且紧凑得多的输入表示的同时,差距不到两个百分点。这项工作的意义不在于它立即超越了现有系统,而在于它证明了中层的、人类可解释的几何基元能够支撑具有竞争力的视觉识别;并且作为副产品,学习到的高斯函数往往聚集在模型认为最具区分度的场景部位,提供了一种像素网格模型无法自然提供的轻量级可解释性。
摘要
我们提出 GVIT,一种分类框架,它摒弃了传统的像素或图块网格输入表示,转而采用一组紧凑的可学习二维高斯函数(2D Gaussians)。每幅图像被编码为数百个高斯函数,其位置、尺度、朝向、颜色和不透明度与在这些表示之上训练的 ViT 分类器联合优化。我们将分类器梯度重新用作建设性引导,引导高斯函数趋向类别显著区域,同时由一个可微渲染器优化图像重建损失。我们证明,借助二维高斯输入表示并结合我们的 GVIT 引导,使用相对标准的 ViT 架构便能逼近传统基于图块的 ViT 的性能,在 ViT-B 架构下于 Imagenet-1k 上达到 76.9% 的 top-1 准确率。
引用
@article{hernandezgvit,
title = {GViT: Representing Images as Gaussians for Visual Recognition},
author = {Hernandez, Jefferson and He, Ruozhen and Balakrishnan, Guha and Berg, Alexander C. and Ordonez, Vicente},
journal = {arXiv preprint arXiv:2506.23532},
url = {https://arxiv.org/abs/2506.23532},
}
自动生成的本文相关问题、主要贡献与局限
本文有助于回答的问题
- 什么是 GViT,它解决了什么问题?GViT 是一种视觉识别框架,它用一组紧凑的可学习二维高斯基元替代固定的像素或图块网格输入,用以检验中层几何表示能否支撑具有竞争力的图像分类。
- 高斯函数是如何学习的?一个去噪高斯编码器预测高斯中心、尺度、朝向、颜色和不透明度,同时一个可微渲染器优化图像重建,而一个 ViT 分类器提供建设性梯度,引导高斯函数趋向类别显著区域。
- GViT 在 ImageNet-1k 上的表现如何?经引导的 GViT-B 模型在 ImageNet-1k 上达到 76.9% 的 top-1 准确率,接近于同等规模、基于图块的 ViT-B/16 所报告的 78.7%,同时使用了一种截然不同的高斯输入表示。
- 为什么分类器梯度引导很重要?论文报告称,引导使 GViT-B 在 ImageNet-1k 上从 73.6% 提升到 76.9%,并对更小的模型也有类似改善,表明任务感知的高斯放置对于让该表示在识别中发挥作用至关重要。
- GViT 是否带来可解释性方面的好处?是的,学习到的高斯协方差和类别区分性注意力图往往集中在与类别相关的图像区域,赋予该表示一种标准图块词元无法自然展现的几何视觉解释。
主要贡献
- 论文引入了一种与 ViT 兼容的图像表示,它基于一组二维高斯基元,而非像素、图块、原始字节或压缩频率系数。
- GViT 提出了一种协同训练方案,其中重建损失保持图像保真度,而分类器梯度则主动将高斯函数重新定位到具有区分度的视觉证据上。
- ImageNet-1k 实验表明,高斯输入可在 ViT-B 骨干网络下达到 76.9% 的 top-1 准确率,优于论文中列出的若干非图块输入替代方案,并与传统的基于图块的 ViT-B/16 相差仅 1.8 个百分点。
- 在 Mini-ImageNet-100 上的消融实验表明,去噪和分类器梯度引导显著改善了高斯放置,完整的引导版本优于离线高斯拟合、可学习查询以及无引导去噪。
- 分析表明高斯尺度和注意力信号与类别区分性区域相吻合,支持了 GViT 提供一种带有自然可解释性成分的紧凑识别表示这一论点。
局限与注意事项
- 对于当今许多大规模部署而言,基于图块的 ViT 仍然是最务实的选择,但 GViT 在 ImageNet-1k 上较小的准确率差距有力地表明,高斯基元已经是一种可行且出人意料地具有竞争力的替代表示。
- 高斯函数的数量在训练前就已固定,因此未来版本可受益于动态生成、剪枝或重新分配;随着高斯预算增加而观察到的单调增益为下一步的设计提供了有用的指引。
- 可微渲染增加了内存和计算开销,尤其是在高分辨率下或在 ImageNet 规模训练中使用超过 512 个高斯函数时;这是围绕一个其余方面颇具前景的表示的工程瓶颈,而非核心思想的弱点。
- 实验聚焦于图像分类和迁移分类基准,而非检测或分割等密集预测任务;类别显著的高斯布局表明,这些任务是接下来探索该表示的自然方向。
- 当前方法在设计上压缩掉了一些细粒度的像素细节,这有助于使表示紧凑且可解释,同时也为未来工作在重建保真度与语义区分度之间调节平衡留下了空间。
如何理解这一结果
这篇论文最好被理解为一个有力的、有证据支撑的论点:视觉识别不必绑定于像素或图块网格——GViT 使 ImageNet 性能逼近标准 ViT,同时引入了一种可解释的高斯表示,为未来的视觉骨干网络开辟了一个颇具前景的方向。